A year and a half ago we embarked on the Open Economics project with the support of the Alfred P. Sloan Foundation and we would like a to share a short recap of what we have been up to.
Our goal was to define what open data means for the economics profession and to become a central point of reference for those who wanted to learn what it means to have openness, transparency and open access to data in economics.

openeconomics.net/advisory-panel/
Advisory Panel
We brought together an Advisory Panel of twenty senior academics who advised us and provided input on people and projects we needed to contact and issues we needed to tackle. The progress of the project has depended on the valuable support of the Advisory Panel.

openeconomics.net/workshop-dec-2012/

openeconomics.net/workshop-june-2013
International Workshops
We also organised two international workshops, first one held in Cambridge, UK on 17-18 December 2012 and second one in Cambridge U.S. on 11-12 June 2013, convening academics, funders, data publishers, information professionals and students to share ideas and build an understanding about the value of open data, the still persisting barriers to opening up information, as well as the incentives and structures which our community should encourage.
Open Economics Principles
While defining open data for economics, we also saw the need to issue a statement on the openness of data and code – the Open Economics Principles – to emphasise that data, program code, metadata and instructions, which are necessary to replicate economics research should be open by default. Having been launched in August, this statement is now being widely endorsed by the economics community and most recently by the World Bank’s Data Development Group.
Projects
The Open Economics Working Group and several more involved members have worked on smaller projects to showcase how data can be made available and what tools can be built to encourage discussions and participation as well as wider understanding about economics. We built the award-winning app Yourtopia Italy – http://italia.yourtopia.net/ for a user-defined multidimensional index of social progress, which won a special prize in the Apps4Italy competition.
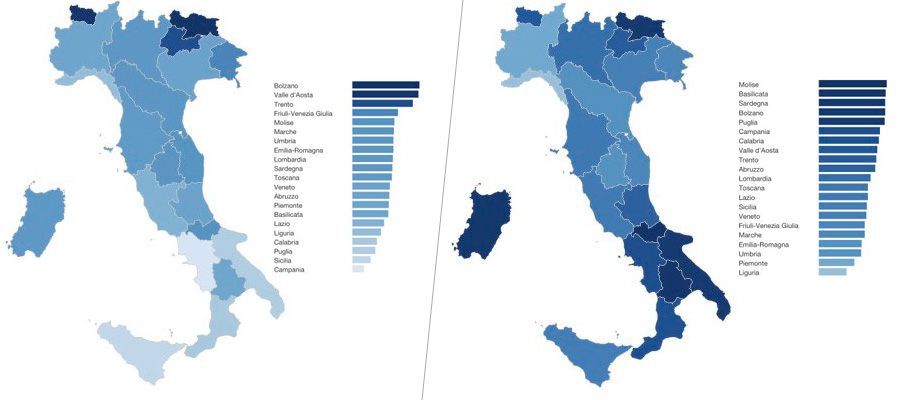
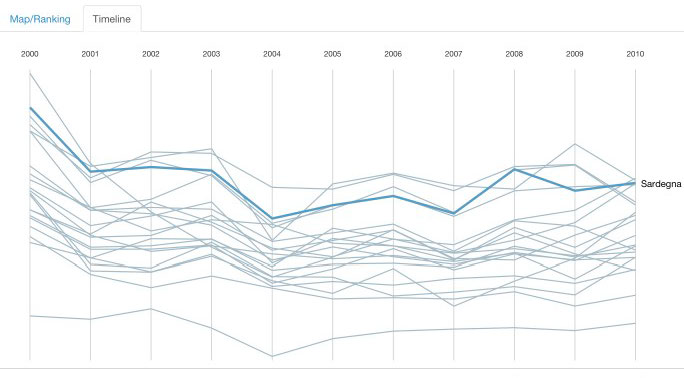
Yourtopia Italy: application of a user-defined multidimensional index of social progress: italia.yourtopia.net
We created the Failed Bank Tracker, a list and a timeline visualisation of the banks in Europe which failed during the last financial crisis and released the Automated Game Play Datasets, the data and code of papers from the Small Artificial Agents for Virtual Economies research project, implemented by Professor David Levine and Professor Yixin Chen at the Washington University of St. Louis. More recently we launched the Metametrik prototype of a platform for the storage and search of regression results in the economics.

MetaMetrik: a prototype for the storage and search of econometric results: metametrik.openeconomics.net
We also organised several events in London and a topic stream about open knowledge and sustainability at the OKFestival with a panel bringing together a diverse range of panelists from academia, policy and the open data community to discuss how open data and technology can help improve the measurement of social progress.

Blog and Knowledge Base
We blogged about issues like the benefits of open data from the perspective of economics research, the EDaWaX survey of the data availability of economics journals, pre-registration of in the social sciences, crowd-funding as well as open access. We also presented projects like the Statistical Memory of Brazil, Quandl, the AEA randomized controlled trials registry.
Some of the issues we raised had a wider resonance, e.g. when Thomas Herndon found significant errors in trying to replicate the results of Harvard economists Reinhart and Rogoff, we emphasised that while such errors may happen, it is a greater crime not to make the data available with published research in order to allow for replication.
Some outcomes and expectations
We found that opening up data in economics may be a difficult matter, as many economists utilise data which cannot be open because of privacy, confidentiality or because they don’t own that data. Sometimes there are insufficient incentives to disclose data and code. Many economists spend a lot of resources in order to build their datasets and obtain an advantage over other researchers by making use of information rents.
Some journals have been leading the way in putting in place data availability requirements and funders have been demanding data management and sharing plans, yet more general implementation and enforcement is still lacking. There are now, however, more tools and platforms available where researchers can store and share their research content, including data and code.
There are also great benefits in sharing economics data: it enables the scrutiny of research findings and gives a possibility to replicate research, it enhances the visibility of research and promotes new uses of the data, avoids unnecessary costs for data collection, etc.
In the future we hope to concentrate on projects which would involve graduate students and early career professionals, a generation of economics researchers for whom sharing data and code may become more natural.
Keep in touch
Follow us on Twitter @okfnecon, sign up to the Open Economics mailing list and browse our projects and resources at openeconomics.net.
Velichka is Project Coordinator of Open Economics at the Open Knowledge Foundation. She is based in London, a graduate of economics (Humboldt Universität zu Berlin) and environmental policy (University of Cambridge) and a fellow of the Heinrich Böll Foundation @vndimitrova








Hi Velichka,
Just reading all the reports and quite a lot of stuff that the Advisory Board members have written. I’m really interested in this as I worked as a Finance broker for 10 years, where most useful data is never obvious. E.g. We know that we are coming into another Financial crisis, due primarily to the dishonesty of (TBTF) To big to Fail banks working around the intent of the Glass Steagall legislation. That’s an education which every American had had. http://www.pbs.org/wgbh/pages/frontline/shows/wallstreet/weill/demise.html
After 4 years of Quantitive Easing, Abenonomics, etc in most of the western economies means we are still in the position we were in 2008, where 40 years of overspending by ‘developed” economies, and their inability of repay their debts, means we must revisit another Financial crisis. We even know that we can trace the cause of the present (US )problems back to the creation of the US Federal reserve – an association of private banks.
So I have to ask, as this crosses the line between open government and open economics. What is the use of knowledge when one can do nothing with it?