Corona Time has brought the eery experience of becoming like a pawn on a chess board. Suddenly where we go, what we do, what we wear, who we meet and why are decided by somebody else. Here in Berlin, our youngest son now goes to school on Tuesday and Thursday mornings while his best friend goes on Mondays and Thursdays. As of this week. Maybe next week it will open up more. Maybe it won’t. Meanwhile our three other children, in different schools, are off until August.
These decisions need to be dynamic and reactive. We know who makes them, more or less: our leaders are all still in place since the last election they won. We just don’t know what the rules are. The only honest campaign promise if an election were held now, anywhere in the world, would be: “We’ll play it by ear.”
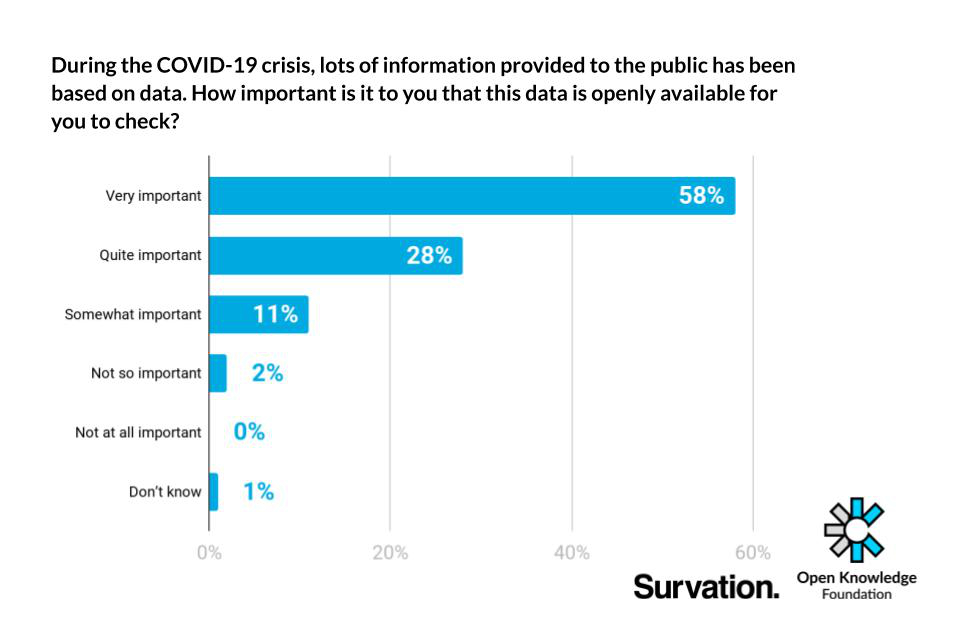
But there are – or for goodness sake should be! – systems which are suggesting those rules to manage the crisis. And because of the incredible complexity, they are being driven by algorithms in models. In the case of lockdown policy, how much to open up is a function of the interaction between many different variables: how many people have been infected so far, the current transmission rate, the properties of the virus itself, some estimates of compliance with various different social distancing options, even the starting position of how a given population is laid out on the chess board in the first place.
And there are plenty of other decisions being driven by models. Who gets the ventilator? What invasions of privacy are justified at any point in time to enforce social distancing? How many people should be tested?
So where are these models? And why can’t we see them? Since democracy has been suspended, along with normal economic life, the models have all to rule. The only way to snatch back even a modicum of the scrutiny that we have lost is to publish the models online.
For three reasons: to make sure that that the models, which are triggering life and death decisions, are sufficiently stress tested; to check that bad stuff isn’t slipping in through the back door, and we don’t end up with a slate of mass surveillance measures that were spuriously justified as saving lives; and to ensure that models are even being used consistently.
To deal with this last point first. It has been clear so far that many leaders are “modelling illiterate”. The UK government lurched from a barely articulated idea of herd immunity into stringent lockdown in late March. But is it in danger now of overkill in the other direction now, keeping a general lockdown going too long? Nobody knows. Debates around policy still lack nuance by and large, assuming static positions (it’s even hard to avoid the suspicion that identity politics plays a role – “What’s all the hysterical overreaction?” or “How come some people don’t care and can’t see how serious this is?”) Whereas the reality is policy is going to continue to need to be driven by equations – what is today’s estimate of the number of infections, beds available etc etc.
In the case of the UK, it has been widely reported that the change was driven by the modelling of Professor Neil Ferguson, at Imperial College, London. At least some other scientists, notably Nobel prize winner Michael Levitt, have challenged the assumptions going into that model, defining the spread of COVID-19 as not exponential but “sub-exponential” after an initial phase, regardless of any policy intervention. But we can’t know who’s right, or even if the government drew the right conclusions from the model, because the version of the model used to drive that decision is not accessible. They might be driving blind.
It’s not as though all of us all are about to download the model, spend hours inspecting it, and list its weak points. That’s not the way transparency works. But imagine: the government announced which model it was using, why it drew the conclusions it did from it, and published the model. And Professor Levitt, and a few dozen others, could beat it up, as scientists do, and offer feedback and improvements to policy makers – in real-time. There is a community of scientists able to form an informed view of the dispute between Ferguson and Levitt, updated with new data day by day, and to articulate that view to the media. In the absence of parliament, that’s the nearest we’re going to get to accountability.
And then we have encroachment. The Open Knowledge Foundation’s new Justice Programme has already made great strides in defining algorithmic accountability, how the rules in models need to be held to democratic account. In some places in the United States, for example, rules have been introduced to give patients access to emergency medical care according to how many years of life they are expected to live, should they survive. Which sounds reasonable enough – until you consider that poverty has a big impact on medical history, which in turn drives life expectancy. So then, in fact, the algorithm ends up picking more affluent patients, and leaving the poor to die. Or the Taiwanese corporation that is introducing cameras to every work station in all its factories – right now, it says, to catch workers who infringe social distancing rules. But who knows?
The coronavirus is dramatic. But in fact it is just one example of a much broader, deeper trend. Although computational modelling has been around for decades – its first significant implementations were in World War Two, to break German military codes and build the nuclear bomb – it has picked up extraordinary pace in the last five to ten years, driven by cheap processing power, big data and other factors. Massive decisions are now being made in every aspect of public life driven by models we never see, whose rules nobody understands.
The only way to re-establish democratic equilibrium is for the models themselves to be published. If we’re going to be moved around like pieces on the chess board, we at least need to see what the rules of the game are. And if the people moving us round the board even understood them.
• Johnny West is director of OpenOil, a Berlin-based consultancy which uses open data and methodologies to build investment-grade financial and commercial analysis for governments and societies of their natural resource assets. He sits on the Advisory Board of FAST, the only open source financial modelling standard, and is an alumnus of the Shuttleworth Foundation Fellowship. He is also a member of the Open Knowledge Foundation’s Board.
Johnny West is director of OpenOil, a Berlin-based consultancy which uses open data and methodologies to build investment-grade financial and commercial analysis for governments and societies of their natural resource assets. He sits on the Advisory Board of FAST, the only open source financial modelling standard, is an alumnus of the Shuttleworth Foundation Fellowship and serves a member of the Open Knowledge Foundation Board of Directors.







