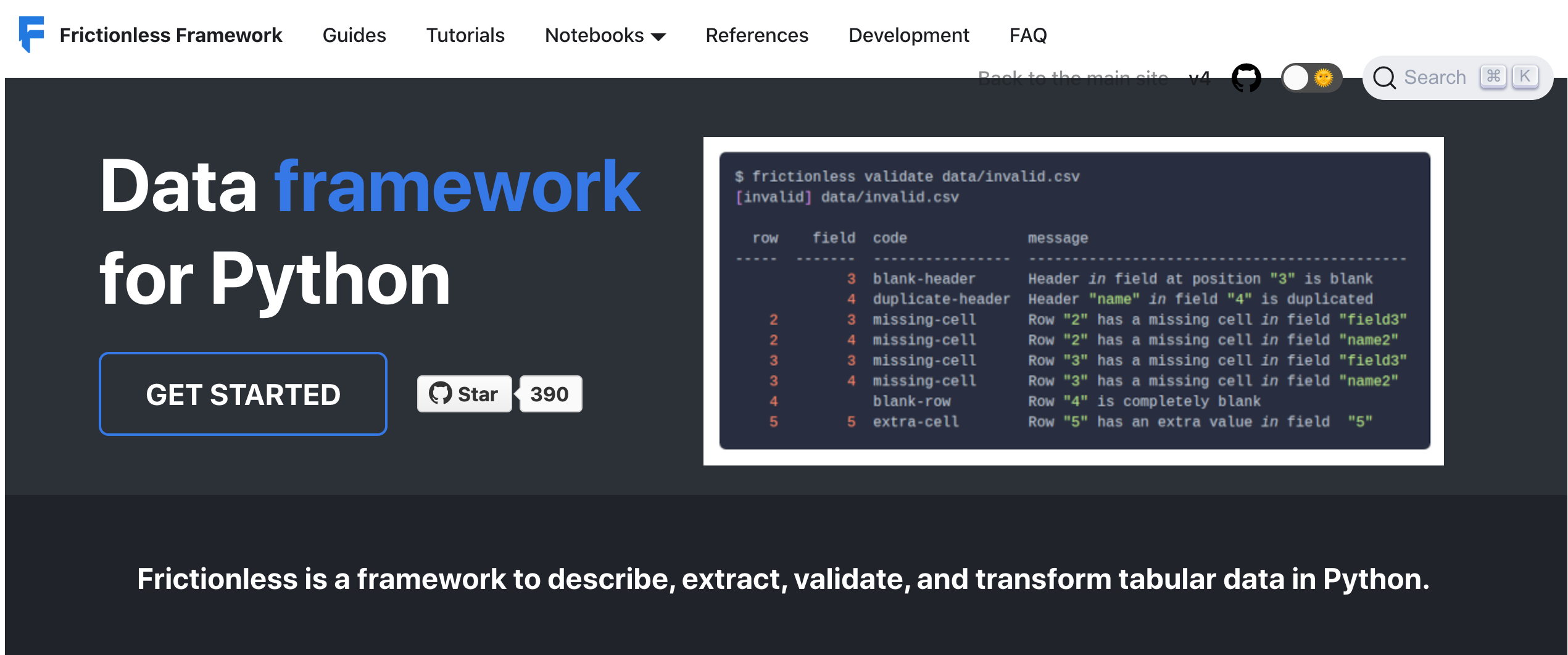
Have you used Frictionless Data documentation in the past and been confused or wanted more examples? Are you a brand new Frictionless Data user looking to get started learning?
We invite you all to visit our new and improved documentation portal.
Thanks to a fund that the Open Knowledge Foundation was awarded from the Open Data Institute, we have completely reworked the guides of our Frictionless Data Framework website according to the suggestions from a cohort of users gathered during several feedback sessions throughout the months of February and March.
We cannot stress enough how precious those feedback sessions have been to us. They were an excellent opportunity to connect with our users and reflect together with them on how to make all our guides more useful for current and future users. The enthusiasm and engagement that the community showed for the process was great to see and reminded us that the link with the community should be at the core of open source projects.
We were amazed by the amount of extremely useful inputs that we got. While we are still digesting some of the suggestions and working out how to best implement them, we have made many changes to make the documentation a smoother, Frictionless experience.
So what’s new?
A common theme from the feedback sessions was that it was sometimes difficult for novice users to understand the whole potential of the Frictionless specifications. To help make this clearer, we added a more detailed explanation, user examples and user stories to our Introduction. We also added some extra installation tips and a troubleshooting section to our Quick Start guide.
The users also suggested several code changes, like more realistic code examples, better explanations of functions, and the ability to run code examples in both the Command Line and Python. This last suggestion was prompted because most of the guides use a mix of Command Line and Python syntax, which was confusing to our users. We have clarified that by adding a switch in the code snippets that allows user to work with a pure Python Syntax or pure Command Line (when possible), as you can see here. We also put together an FAQ section based on questions that were often asked on our Discord chat. If you have suggestions for other common questions to add, let us know!
The documentation revamping process also included the publication of new tutorials. We worked on two new Frictionless tutorials, which are published under the Notebooks link in the navigation menu. While working on those, we got inspired by the feedback sessions and realised that it made sense to give our community the possibility to contribute to the project with some real life examples of Frictionless Data use. The user selection process has started and we hope to get the new tutorials online by the end of the month, so stay tuned!
What’s next?
Our commitment to continually improving our documentation is not over with this project coming to an end! Do you have suggestions for changes you would like to see in our documentation? Please reach out to us or open a pull request to contribute. Everyone is welcome to contribute! Learn how to do it here.
Thanks, thanks, thanks!
Once again, we are very grateful to the Open Data Institute for giving us the chance to focus on this documentation in order to improve it. We cannot thank enough all our users who took part in the feedback sessions. Your contributions were precious.
More about Frictionless Data
Frictionless Data is a set of specifications for data and metadata interoperability, accompanied by a collection of software libraries that implement these specifications, and a range of best practices for data management. The project is funded by the Sloan Foundation.

Sara works with communities. She leads the Open Knowledge Network and manages the Frictionless Data community. Before joining Open Knowledge Foundation, she has worked on free access to information and quality education for all with public libraries from all across Europe.







