The following guest post is from Stefan Urbanek, an independent consultant, analyst, and member of the Open Knowledge Foundation’s Working Group on Open Government Data. You can meet him in person at Open Government Data Camp in London this November!
Introduction
“The Ministry of Defense of the Slovak Republic is a government department which is doing the most public procurements, and the minister cannot know about all of them. He would have gone crazy if he did” said spokesman of former minister of defense just couple of weeks ago. It is like if spokesman of a supermarket chain said: “The SuperSuperMarket chain has the most suppliers and is doing the most supplies of all super market chains. Our CEO can not know about all of them. He would have gone crazy if he did”. Still, he somehow knows: from reports, dashboards, scorecards.
Public Procurement Office in Slovakia is obliged by law to publish bulletins with public procurement announcements online and they are doing it on “e-procurement” site. There are archived bulletins since 2001, with new publishing system since January 2009. Visitors can browse announcements chronologically by bulletin. Only the new system is searchable and only by bulletin number. To find or summarize particular information the visitor has to go through all the bulletins, one-by-one. In other words, summarizing and searching is near to impossible.
The Project
Transparency International Slovakia is initiating projects for open governmental data and one of the very recent projects, which went into beta public release in September 2010 was the Open Public Procurements reporting site. The primary goal of the site is to be able to see the spending of governmental institutions: what they spend on, who does the projects and receives the money, what kind of procurement process was used, and so on.
The objectives of the project are to:
- provide, and therefore extract as much information as possible
- maintain certain level of data quality or at least know about data quality limitations
- be able to aggregate the data
- be able to search in the data
- provide raw data
- open up the possibility to incorporate older bulletins from archives
Visitors are able to see aggregated data since 2009 from the new e-procurement publishing system. They can change their point of view to organisation, supplying company, any level of procurement subject type or any other dimension. It is also possible to see all contracts within selected slice of data, as well as get them as raw data (CSV for details or aggregated data) for further processing. The contract dimensions can be fully searched, therefore one can find for example all procurements of Ministry of Defense in 2009.
Data Source
There is no raw data source for public procurement contracts. All bulletin pages are published as HTML documents, which are nicely human-readable, but hardly machine processable. The internal document structure is weird: it does not look generated by combining database fields with document template.
To extract the data from documents, we can not rely safely on document tree structure, neither on element IDs, which are mostly non-existent, or misused. Even though many documents seem to have similar structure, there are way too many exceptions and changes in wording and labels to believe that their primal store has data as raw data. Therefore for document parsing we used combination of tolerance for volatile tree structure, multiple pattern matching for fields (more patterns for same field label) and kind of state-machine processing.

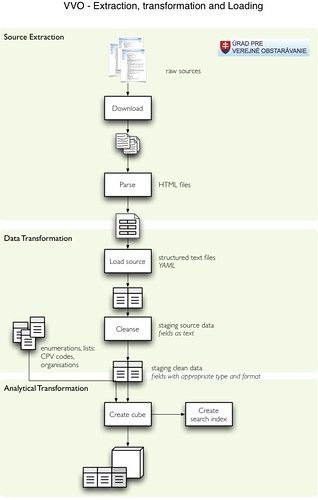
We managed to get around 65 attributes from documents with varying completeness quality. The fields include, for example:
- procuring organization (99% completeness and correctness)
- supplier (99,5% completeness, 95% correctness)
- contracted amount (96% completeness)
- procurement process type (66% completeness)
- procurement subject based on European Common Procurement Vocabulary (CPV)
- many more
As you may see, we measured data quality dimensions during the process. Which helped us to not only to fine-tune the extraction, but also to find interesting facts. For example, we thought that the 66% completeness of procurement process type (public competition, closed selection, …) is just extraction problem and we have to add another rule or exception. After deeper analysis we found, that the bulletin documents are really missing information about procurement process type.
Processing
Announcement documents are being processed in a chain-dependent steps: extraction (downloading and parsing into structured form), raw data transformation (loading into database, cleansing) and analytical transformation (create analytical structure, build search index). Reasons for splitting the data processing instead of creating single monolithic processing script are mainly:
- easier to maintain, upgrade and fix
- possible to re-run part of the chain from failed or fixed node
- re-running parts of the chain also lowers load on server hosting the application as well as server of Public Procurement Office (no need to download again after a fix)
- possible to plug-in other sources into the chain, even they would be run once, such as historical data from archive
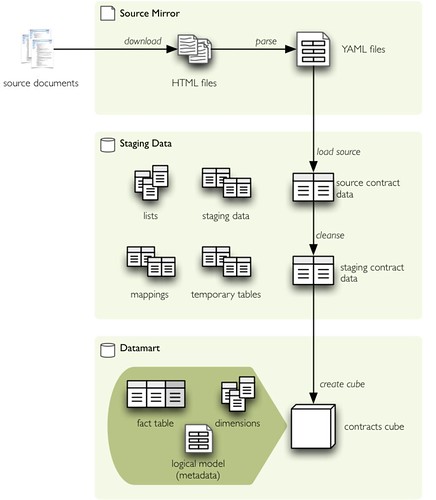
All intermediate results are being kept, therefore we have three data stores:
- source mirror contains downloaded original documents and parsed structured version of the documents in YAML format. If the source becomes unavailable and it is desired to parse the files again (more attributes gathered, different parsing method, bug fix), it can be done on locally stored files
- staging data are data stored in database, besides contract data (raw and cleansed) they contain various lists, reference codes and mappings (for consolidating enumerations or cleansing organisations). staging data store also contains mappings for unknown organisations that can be fixed manually
- data-mart data store for contains final data for the application
Public Procurements Datamart
Final product of the process is the “public procurements data mart”: data structures that can be used for analysis and reporting. More specifically, the datamart store contains:
- contracts as facts in snowflake schema
- description of logical data model – metadata, human readable description of data (labels, dimensions, hierarchies)
- dimension tables, such as governmental organisations, suppliers or procurement subjects (CPV)
For the Open Public Procurements portal we have used online analytical processing (OLAP) approach with multidimensional logical model. Advantages of this approach:
- data analysis is easier and faster
- we can change data hierarchies without changing the final application, for example it would not be difficult to add “quarter” to the date dimension or “organisation type” to an organisation. Note that the subject in CPV already has 5 levels in its hierarchy: division, group, class, category, detail)
- thanks to open metadata we can later build and use more generic analytical tools on top of the data

The Application
The application was built as data presentation layer in Ruby on Rails (without Active Record). It reads description of the datamart logical data model and presents data accordingly to the model. Charts are provided by the Google Charts API, for searching we used Sphinx search engine.
Conclusion and Next Steps
We managed to transform unstructured, not machine-processable-ready documents into neat structured data that can be used for analytical processing. Moreover, we reached decent levels quality or at least we can explain most of the quality issues. The Open Public Procurements portal of Transparency International Slovakia is currently the most complete statistical and open raw data source of public procurements in Slovakia. Moreover, it is live – updated daily. Within the first few weeks of its beta launch, the site got almost 600 unique visitors. It is quite a nice number considering, that the site was not announced widely in any newspaper yet, only within small community of “domain experts in transparency”.
What we plan next is to try to process and include older years from Public Procurements Office archives, merge other types of documents and to localize the application. Furthermore, the data is going to be used in other transparency projects as well.
By the way, to add some information to my opening quote: our Ministry of Defense has spent €118,044,902.80 in 2009 in 310 contracts where 20% was spending on electricity through one contract with single supplier. They contracted 56% of the amount through public competition and 36% of the amount without publishing the procuring process. We know that thanks to the Open Public Procurements portal.
This post is by a guest poster. If you would like to write something for the Open Knowledge Foundation blog, please see the submissions page.








interesting project. Could you apply it to the EU portal of public procurement? it covers all EU member states. ted.europa.eu