The Frictionless Data project is about making it effortless to transport high quality data among different tools and platforms for further analysis. We are doing this by developing a set of software, specifications, and best practices for publishing data. The heart of Frictionless Data is the Data Package specification, a containerization format for any kind of data based on existing practices for publishing open-source software.
The Frictionless Data case study series highlights projects and organisations who are working with Frictionless Data specifications and software in interesting and innovative ways. OpenML is one such organization. This case study has been made possible by OpenML’s Heidi Seibold and Joaquin Vanschoren, the authors of this blog.
![]()
OpenML is an online platform and service for machine learning, whose goal is to make machine learning and data analysis simple, accessible, collaborative and open with an optimal division of labour between computers and humans. People can upload and share data sets and questions (prediction tasks) on OpenML that they then collaboratively solve using machine learning algorithms.
We first heard about the Frictionless Data project through School of Data. One of the OpenML core members is also involved in School of Data and used Frictionless Data’s data packages in one of the open data workshops from School of Data Switzerland.
We offer open source tools to download data into your favourite machine learning environments and work with it. You can then upload your results back onto the platform so that others can learn from you. If you have data, you can use OpenML to get insights on what machine learning method works well to answer your question. Machine Learners can use OpenML to find interesting data sets and questions that are relevant for others and also for machine learning research (e.g. learning how algorithms behave on different types of data sets).
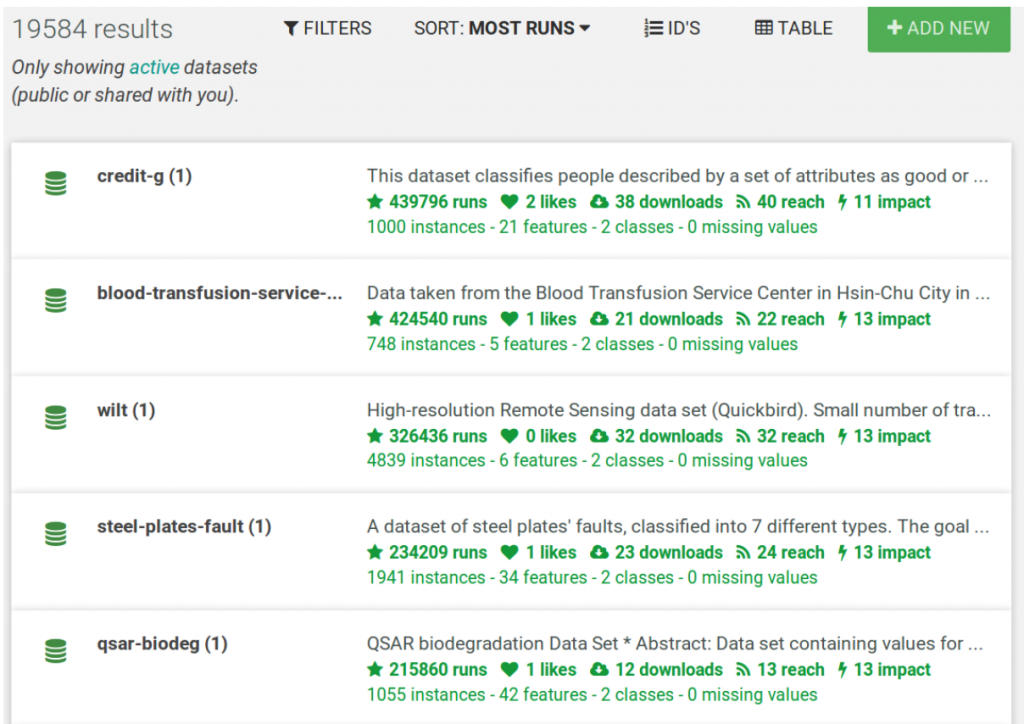
OpenML currently works with tabular data in Attribute Relation File Format (ARFF) accompanied by metadata in an xml or json file. It is actually very similar to Frictionless Data’s tabular data package specification, but with ARFF instead of csv.
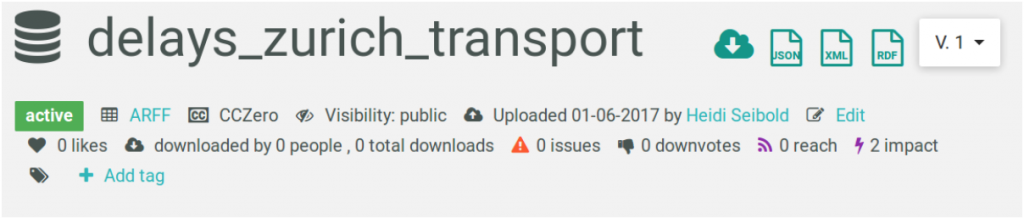
In the coming months, we are looking to adopt Frictionless Data specifications to improve user friendliness on OpenML. We hope to make it possible for users to upload and connect datasets in data packages format. This will be a great shift because it would enable people to easily build and share machine learning models trained on any dataset in the frictionless data ecosystem.
We firmly believe that if data packages become the go-to specification for sharing data in scientific communities, accessibility to data that’s currently ‘hidden’ in data platforms and university libraries will improve vastly, and are keen to adopt and use the specification on OpenML in the coming months.
Interested in contributing to OpenML’s quest to adopt the data package specification as an import and export option for data on the OpenML platform? Start here.
I am assistant professor of Machine Learning at the Eindhoven University of Technology. My research focuses on the automation of machine learning and networked science. I founded OpenML.org, a collaborative machine learning platform where scientists can automatically log and share data, code, and experiments, and which automatically learns from all this data to help people perform machine learning better and easier. My other passion is large-scale data analysis on all types of data (social, streams, geo-spatial, sensors, networks, text).







