In August 2018, Serah Rono will be running a Frictionless Data workshop in CopenHagen, congregated by the Danish National Research Data Management Forum as part of the FAIR Across project. In October 2018, she will also run a Frictionless Data workshop at FORCE11 in Montreal, Canada. Ahead of the two workshops, and other events before the close of 2018, this blog post discusses how the Frictionless Data initiative aligns with FAIR research principles.
An integral part of evidence-based research is gathering and analysing data, which takes time and often requires skill and specialized tools to aid the process. Once the work is done, reproducibility requires that research reports be shared with the data and software from which insights are derived and conclusions are drawn, if at all. Widely lauded as a key measure of research credibility, reproducibility also makes a bold demand for openness by default in research, which in turn fosters collaboration.
FAIR (findability, accessibility, interoperability and reusability) research principles are central to the open access and open research movements.
“FAIR Guiding Principles precede implementation choices, and do not suggest any specific technology, standard, or implementation-solution; moreover, the Principles are not, themselves, a standard or a specification. They act as a guide to data publishers and stewards to assist them in evaluating whether their particular implementation choices are rendering their digital research artefacts Findable, Accessible, Interoperable, and Reusable.”
Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data3:160018 doi: 10.1038/sdata.2016.18 (2016)
Data Packages in Frictionless Data as an example of FAIRness
Our Frictionless Data project aims to make it effortless to transport high quality data among different tools & platforms for further analysis. The Data Package format is at the core of Frictionless Data, and it makes it possible to package data and attach contextual information to it before sharing it.
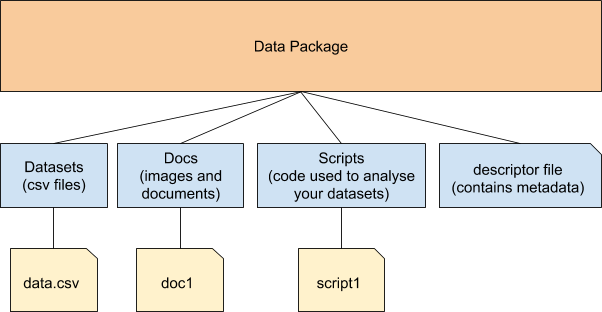
Data packages are nothing without the descriptor file. This descriptor file is made available in a machine readable format, JSON, and holds metadata for your collection of resources, and a schema for your tabular data.
Findability
In Data Packages, pieces of information are called resources. Each resource is referred to by name and has a globally unique identifier, with the provision to reference remote resources by URLs. Resource names and identifiers are held alongside other metadata in the descriptor file.
Accessibility
Since metadata is held in the descriptor file, it can be accessed separately from associated data. Where resources are available online – in an archive or data platform – sharing the descriptor file only is sufficient and data provenance is guaranteed for all associated resources.
Interoperability
The descriptor file is saved as a JSON file, a machine-readable format that can be processed with great ease by many different tools during data analysis. The descriptor file uses accessible and shared language, and has provision to add descriptions, and information on sources and contributors for each resource, which makes it possible to link to other existing metadata and guarantee data provenance. It is also very extensible, and can be expanded to accommodate additional information as needed.
Reusability
Part of the metadata held in a data package includes licensing and author information, and has a requirement to link back to original sources thus ensuring data provenance. This serves as a great guide for users interested in your resources. Where licensing allows for resources to be archived on different platforms, this means that regardless of where users access this data from, they will be able to trace back to original sources of the data as needed. For example, all countries of the world have unique codes attached to them. See how the Country Codes data package is represented on two different platforms: GitHub, and on DataHub.
With thanks to SLOAN Foundation for the new Frictionless Data For Reproducible Research grant, we will be running deep dive workshops to expound on these concepts and identify areas for improvement and collaboration in open access and open research. We have exciting opportunities in store, which we will announce in our community channels over time.
Bonus readings
Here are some of the ways researchers have adopted Frictionless Data software in different domains over the last two years:
- The Cell Migration and Standardisation Organisation (CMSO) uses Frictionless Data specs to package cell migration data and load it into Pandas for data analysis and creation of visualizations. Read more.
- We collaborated with Data Management for TEDDINET project (DM4T) on a proof-of-concept pilot in which we used Frictionless Data software to address some of the data management challenges faced by DM4T. Read more.
- Open Power System Data uses Frictionless Data specifications to avail energy data for analysis and modeling. Read more.
- We collaborated with Pacific Northwest National Laboratory – Active Data Biology and explored use of Frictionless Data software to generate schema for tabular data and check validity of metadata stored as part of a biological application on GitHub. Read more.
- We collaborated with the UK Data service and used Frictionless Data software to assess and report on data quality, and made a case for generating visualisations with ensuing data and metadata. Read more.
Our team is also scheduled to run Frictionless Data workshops in the coming months:
- In CopenHagen, congregated by the Danish National Research Data Management Forum as part of the FAIR Across project, in August 2018.
- In Montreal, Canada, at FORCE11 between October 10 and 12, 2018. See the full program here and sign up here to attend the Frictionless Data workshop.
Developer Advocate, Open Knowledge Foundation







