The Global Open Data Index (GODI) is one of our core projects at Open Knowledge International. The index measures and benchmarks the openness of government data around the world. Brook Elgie shares a behind-the-scenes look at the technical design of how we gather the data for the Index through our extensive Open Data Survey and how other organisations can use this survey codebase for their own purposes.
The Global Open Data Index Survey is an annual survey of the state of government open data around the world. The survey asks a series of questions about the availability and quality of a set of key datasets. As well as providing a valuable snapshot of the state of open data around the world, it also promotes discussion and engagement between government and civil society organisations.
This year Open Knowledge International made changes to the methodology and structure of the survey, and it was an ideal opportunity to revisit the way questions are handled technically within the survey codebase. As well as the survey for the Global Open Data Index, the same codebase hosts surveys for ‘local’ sites, for example, an individual country, or city administration.

Previously, the questions presented for each dataset were a hard-coded feature of the survey codebase. These questions were inflexible and couldn’t be tailored to the specific needs of an individual site. So, while each local site could customise the datasets they were interested in surveying, they had to use our pre-defined question set and scoring mechanisms.
We also wanted to go beyond simple ‘yes/no’ question types. Our new methodology required a more nuanced approach and a greater variety of question types: multiple-choice, free text entry, Likert scales, etc.
Also important is the entry form itself. The survey can be complex but we wanted the process of completing it to be clear and as simple as possible. We wanted to improve the design and experience to guide people through the form and provide in-context help for each question.
Question Sets
The previous survey hard-coded the layout order of questions and their behaviour as part of the entry form. We wanted to abstract out these details from the codebase into the CMS, to make the entry form more flexible. So we needed a data structure to describe not just the questions, but their order within the entry form and their relationships with other questions, such as dependencies. So we came up with a schema, written in JSON. Take this simple set of yes/no questions:
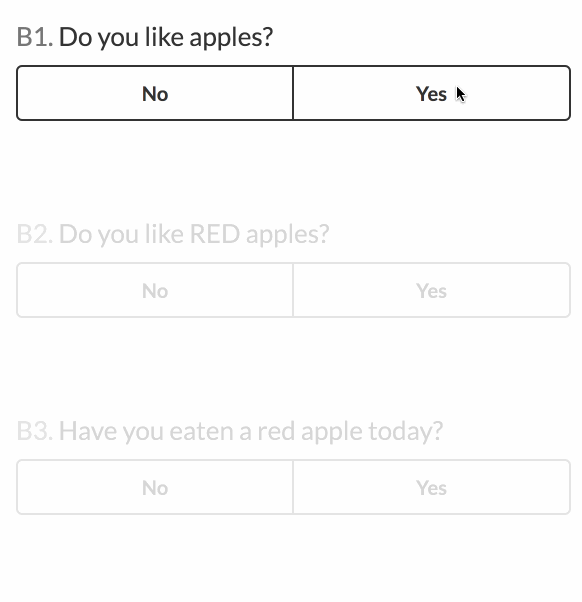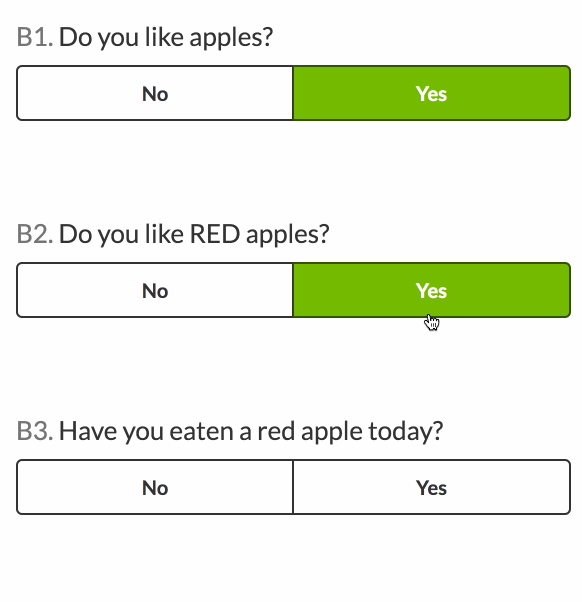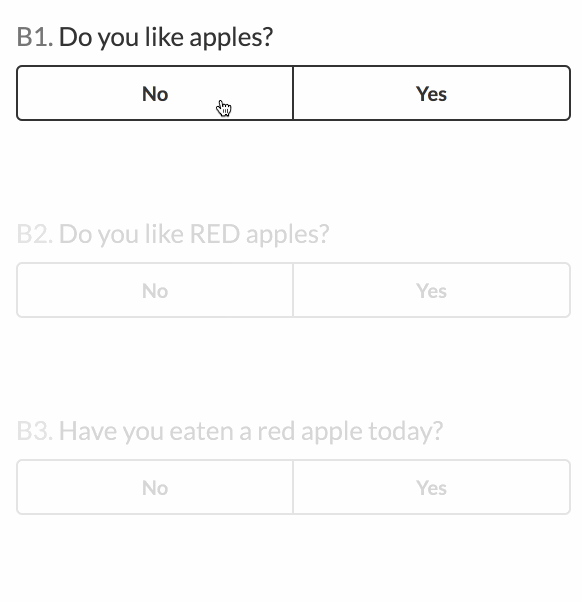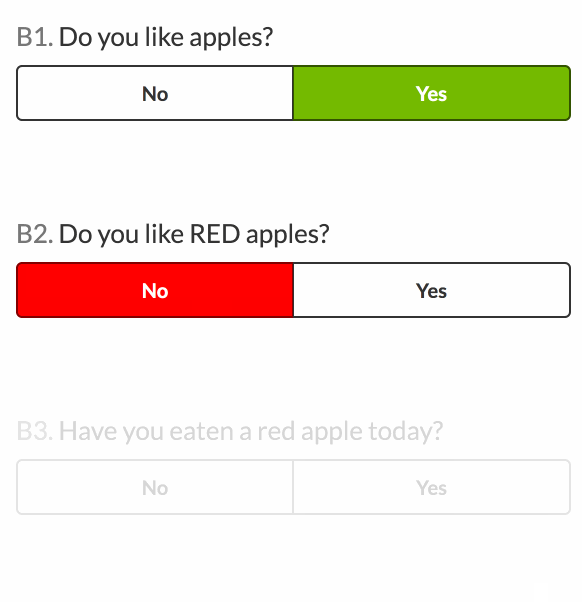
- Do you like apples?
- Do you like RED apples? (initially disabled, enable if 1 is ‘Yes’)
- Have you eaten a red apple today? (initially disabled, enable if 2 is ‘Yes’)
We want to initially display questions 1, 2, and 3, but questions 2 and 3 should be disabled by default. They are enabled once certain conditions are met. Here is what the form looks like:
And this is the Question Set Schema that describes the relationships between the questions, and their position in the form:
Each question has a set of default properties, and optionally an ifProvider structure that defines conditional dependent features. Each time a change is made in the form, each question’s ifProvider should be checked to see if its properties need to be updated.
For example, question 2, apple_colour, is initially visible, but disabled. It has a dependency on the like_apples question (the ‘provider’). If the value of like_apples is Yes, apple_colour‘s properties will be updated to make it enabled.
React to the rescue
The form is becoming a fairly complex little web application, and we needed a front-end framework to help manage the interactions on the page. Quite early on we decided to use React, a ‘Javascript library for building user interfaces’ from Facebook.
React allows us to design simple components and compose them into a more complex UI. React encourages a one-way data flow; from a single source of truth, passed down into child components via properties. Following this principle helped identify the appropriate location in the component hierarchy for maintaining state; in the top level QuestionForm component.
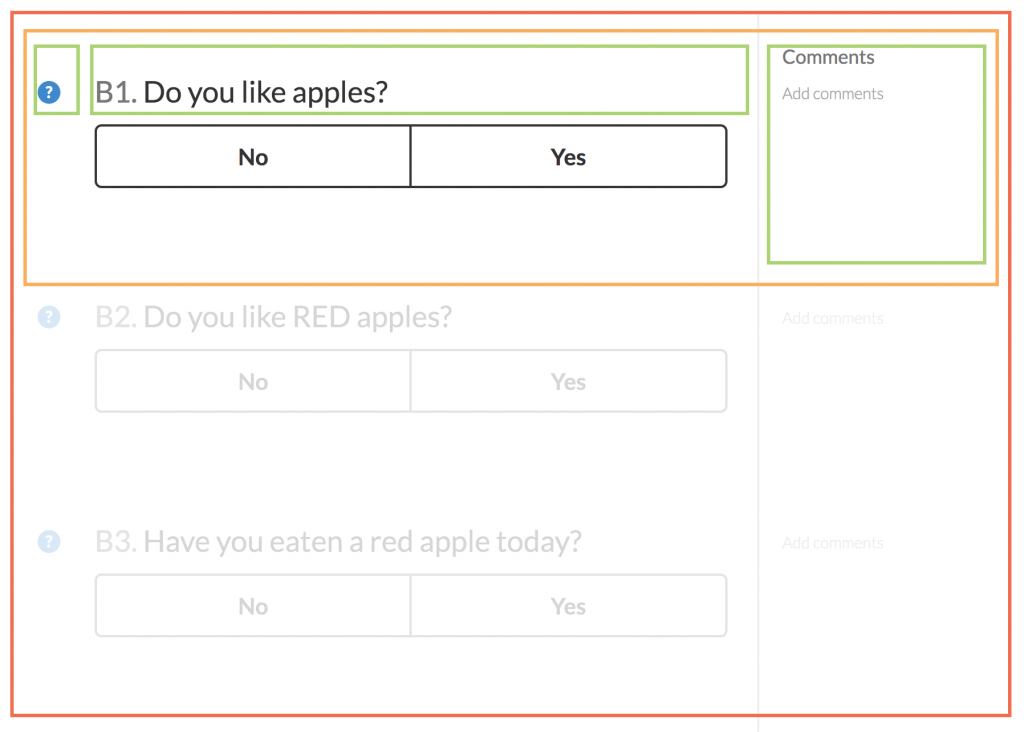
Component’s hierarchy for the entry form:
- QuestionForm (red)
- QuestionField (orange)
- Sub-components: QuestionInstructions, QuestionHeader, and QuestionComments (green)
Changing values in the QuestionFields will update the state maintained in the QuestionForm, triggering a re-render of child components where necessary (all managed by React). This made it easy for one QuestionField to change its visible properties (visibility, enabled, etc) when the user changes the value of another field (as determined by our Question Set Schema).
You can see the code for the entry form React UI on Github.
Some other benefits of using React:
- it was fairly easy to write automated tests for the entry form, using Enzyme
- we can render the initial state of the form on the server and send it to the page template using our web application framework (Express)
Developing in the Open
As with all of Open Knowledge International’s projects, the Open Data Survey is developed in the Open and available as Open Source software: Open Data Survey on Github.
Brook is a Senior Developer with Open Knowledge Foundation.







