The Fiscal Data Package is a lightweight and user-oriented format for publishing and consuming fiscal data. Fiscal Data Packages are made of simple and universal components, are extremely flexible, can be produced from ordinary spreadsheet software and used in any environment.
This specification started about five years ago with a first version (then known as the “Budget Data Package”). Since then we’ve made quite a few iterations, until a fairly stable version was reached, which we name ‘version 0.3’. This version was field-tested in various use cases and scenarios – most prominent among them is the Government of Mexico, who adopted Fiscal Data Package to be used for publishing their official budget data.
For the past six months we’ve been hard at work in reshaping this specification to make it simpler to use and easier to adopt, while improving its flexibility and extensibility – thus making it relevant for more users. In many ways, this new version is the result of the collected experience and lessons learned in the past few years, working with partners and understanding what works and what doesn’t.
So what is the Fiscal Data Package philosophy?
The basic motivation behind Fiscal Data Package is to create a specification which is open by nature – based on other open standards, supported by open tools and software, modular, extensible and promoted transparently by a large community.
The Fiscal Data Package is designed to be lightweight and simple to use – providing a small but flexible set of features, based on real-world requirements and not theoretical ones. All the while, the built-in extensibility allows this spec to adapt to many different use cases and domains. It is also possible to gradually use more and more part of this specification – progressive enhancement – thus making it easier to implement with existing data while slowly improving the data quality.
A main concern we wanted to tackle was the ability to work with data as it currently exists, without forcing publishers to modify the contents or structure of their current data files in order to “adapt” them to the specification. This is a big deal, as publishers often publish data that’s the output of existing internal information systems, and requiring them to do any sort of data cleaning or wrangling on the data prior to uploading in a major source of friction for adoption.
And what is it not?
With that in mind, it’s also important to understand what this specification doesn’t handle. This specification is, by design, non-opinionated about which data should be published by publishers – which datasets, which fields and and the internal processes these reflect.
The only things Fiscal Data Package is concerned with are how fiscal data should be packaged and providing means for publishers to best convey the meaning of the data – so it can be optimally used by consumers. In addition to that, it provides details regarding file-formats, data-types, metadata and structuring the data in files.
What we learned
As previously mentioned, via a wide range of technical implementations, partner piloting, and fiscal data projects with other civic tech and data journalist partners, we’ve learned a lot about what works in Fiscal Data Package v0.3, and what does not. We want to take these learnings and make a more robust and future proof v1.0 of the specification.
One of the first thing we noticed wasn’t working was fiscal modelling. Version 0.3 of the specification contained an elaborate system for the modelling of fiscal data. In practice, this system turned out to be too complicated for normal users and error prone (inconsistent models could be created).
To add to that, modelling was not versatile enough to account for the very different source files existing with real users, nor was it expressive enough to convey the specific semantics required by these users.
A few examples of this strictness include:
- The predefined set of classifications for dimensions. This hard-coded list did not capture the richness of fiscal data ‘in the wild’, as it contained too few and too broad options.
- Measure columns were assumed to be of a specific currency, disregarding datasets in which the currency is provided in a separate column (or non monetary measures).
- Measure columns were assumed to be of a specific budgeting phase (out of 4 options) and of a single direction (income/expenditure), ignoring data sets which have different phases, or that the phase or direction are provided in a separate column – or data sets which are not related to budgets altogether…
Another lesson learned is about file formats. Contrary to what its name might suggest, the world of fiscal data files is a wild jungle – every sort and form of file exists there (if you just look hard enough).
Now, while machines will always prefer to read data files in their denormalised (or unpivoted) form – as it’s the most verbose and straightforward one – publishers will often choose a more compact, pivoted form – and as the proverb goes, there is more than one way to pivot a table. Other publishers would take out from the file some of the data, and append it as a separate code list file, or split large files based on year, budget direction or department.
Version 0.3 of the specification assumed data files would only be provided in a very specific pivoted form – which might apply to some cases, but practically failed on many other variations that we’ve encountered.


What new features does Fiscal Data Package v1.0 provide?
First of all, it introduces a novel and simple way for supporting a wide variation of data file structures – pivoted and unpivoted, with code-lists and without them, provided in a single file or spanning across multiple files.
To do that we’ve added 3 different devices:
- We added the concept of ‘constant fields’: while still supporting any form of metadata added to the Fiscal Data Package descriptor, adding a field with some constant data is often a cleaner and more complete way for adding missing information to the dataset.
- Added built-in facility for ‘unpivoting’ (or de-normalising) the source data: data is no longer expected to be provided in a very specific pivoted form – any structure of the data is now supported.
- Use of Foreign Keys for allowing use of code-lists as part of the specification.
When we know the structure of the data, it allows us to bring all datasets to a single structure. This is crucial for comparisons – how can we compare two datasets when their structure is different?
When the structure is known, it’s easier to ask questions about the data and easily refer to a single data point in the data (e.g. “what was the allocated budget for this contract in 2016?”).
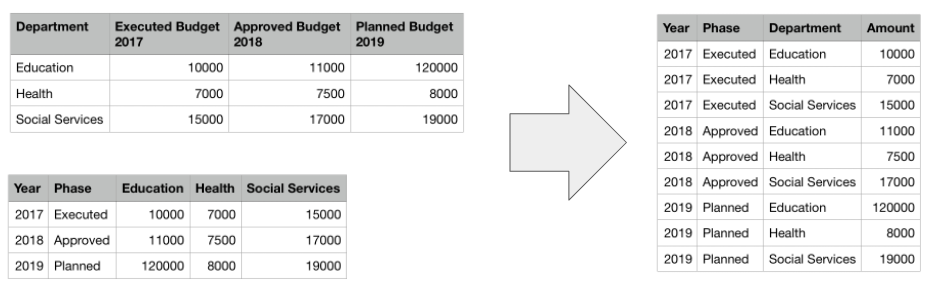
The second big feature of Version 1 is the introduction of ColumnTypes.
ColumnTypes are a lightweight taxonomy for describing the columns of a fiscal data file – that is, not the concepts but their representations. For example, these types are not concerned with ‘Deficit’, ‘Supplier’ or ‘Economic classification’ – these are fiscal concepts. However, when put into a data file, columns such as ‘Supplier last name’ or ‘Title of 2nd level of func. class. in Dutch’ might be used. ColumnTypes are concerned with the data files themselves – and provide a way to extract the concept out of the columns.
ColumnTypes can be combined into taxonomies of similarly-themed types. In these taxonomies, it’s possible to define some relationships between different types – for example, indicate a few ColumnTypes are parts of a more abstract concept. It’s also possible to assign data types and validation rules to a ColumnType, and more.
Alongside this specification we’re also releasing two fiscal taxonomies which serve as standards for publishing budget files and spending files. These can be found here:
What’s next?
This announcement is of a release candidate – we’re looking forward for getting feedback and collaborating with the open-data and fiscal-standard communities. We’re planning to update existing tools (such as OpenSpending) and to build new tools to support this specification and provide integrations for other systems.
Lastly – all this work wouldn’t have been available without the support and collaboration with our partners – chief among them are GIFT – Global Initiative for Fiscal Transparency, as well as the International Budget Partnership, Omidyar Network, google.org, The World Bank, the Government of Mexico and many other pilot governments. We thank them all for generous support in making this work possible.
We really believe that Fiscal Data Package is an opportunity for governments and organisations that see the benefit in publishing budgets to foster transparency as part of a liberal democracy. You are invited to join us on this journey, which many government partners such as Croatia, Guatemala, Burkina Faso and Mexico have already started.
It is needed more than ever.
Adam is an experienced technologist and open data activist, with over 25 years of experience in a wide range of areas - from embedded systems, through mobile applications, scalable services, big data analysis through to UI design. He currently works for Open Knowledge Foundation as Senior Developer and OpenSpending Technical Lead.







