Data Containerisation hits v1.0! Announcing a major milestone in the Frictionless Data initiative.
Today, we’re announcing a major milestone in the Frictionless Data initiative with the official v1.0 release of the Frictionless Data specifications, including Table Schema and Data Package, along with a robust set of pre-built tooling in Python, R, Javascript, Java, PHP and Go.
Frictionless Data is a collection of lightweight specifications and tooling for effortless collection, sharing, and validation of data. After close to 10 years of iterative work on the specifications themselves, and the last 6 months of fine-tuning v1.0 release candidates, we are delighted to announce the availability of the following:
- v1.0 specifications including Table Schema, CSV Dialect, Data Package, and Data Resource.
- Code libraries that implement the v1.0 specifications in Python, Javascript, Ruby, and PHP, with R, Go, and Java in active development.
We want to thank our funder, the Sloan Foundation, for making this release possible.
What’s inside
A brief overview of the main specifications follows. Further information is available on the specifications website.
- Table Schema: Provides a schema for tabular data. Table Schema is well suited for use cases around handling and validating tabular data in plain text formats, and use cases that benefit from a portable, language agnostic schema format.
- CSV Dialect: Provides a way to declare a dialect for CSV files.
- Data Resource: Provides metadata for a data source in a consistent and machine-readable manner.
- Data Package: Provide metadata for a collection of data sources in a consistent and machine-readable manner.
The specifications, and the code libraries that implement them, compose to form building blocks for working with data, as illustrated with the following diagram.
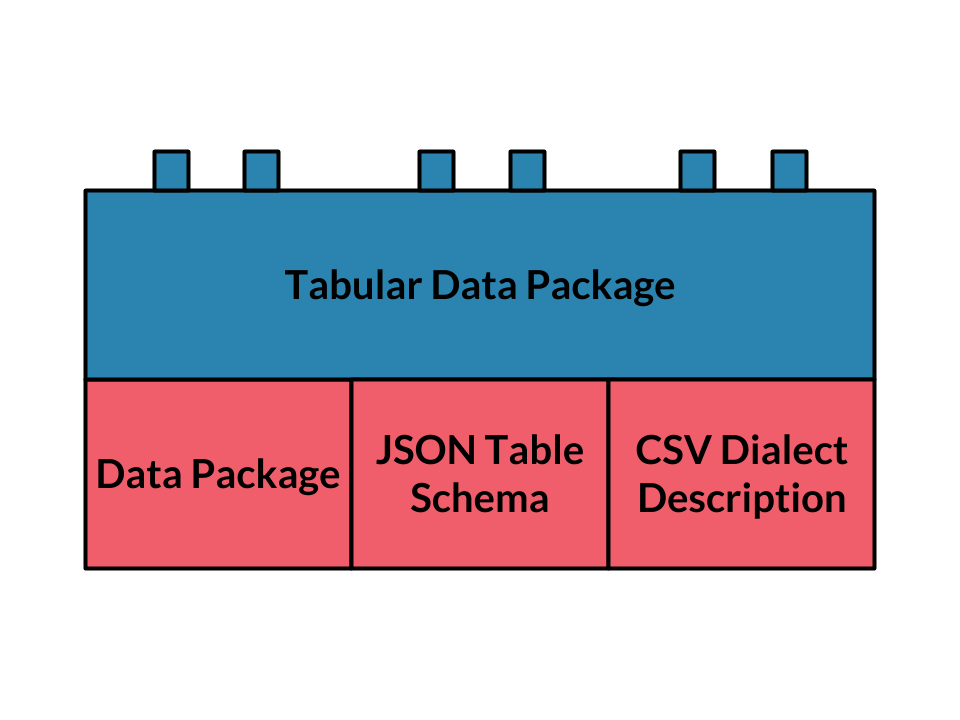
This component based approach lends itself well to the type of data processing work we often encounter in working with open data. It has also enabled us to build higher-level applications that specifically target common open data workflows, such as our goodtables library for data validation, and our pipelines library for declarative ETL.
v1.0 work
In iterating towards a v1 of the specifications, we tried to sharpen our focus on the design philosophy of this work, and not be afraid to make significant, breaking changes in the name of increased simplicity and utility.
What is the design philosophy behind this work, exactly?
- Requirements that are driven by simplicity
- Extensibility and customisation by design
- Metadata that is human-editable and machine-usable
- Reuse of existing standard formats for data
- Language-, technology- and infrastructure-agnostic
In striving for these goals, we removed much ambiguity from the specifications, cut features that were under-defined, removed and reduced various types of optionality in the way things could be specified, and even made some implicit patterns explicit by way of creating two new specifications: Data Resource and Tabular Data Resource.
See the specifications website for full information.
Next steps
We are preparing to submit Table Schema, Data Resource, Data Package, Tabular Data Resource and Tabular Data Package as IETF RFCs as soon as possible.
Lastly, we’ve recently produced a video to explain our work on Frictionless Data. Here, you can get a high-level overview of the concepts and philosophy behind this work, presented by our President and Co-Founder Rufus Pollock.
Paul is the CEO at Datopian







