We are pleased to announce our latest report ‘Avoiding data use silos – How governments can simplify the open licensing landscape’. This report outlines the problems of an ever-growing complexity of open licences, the risk of data use silos, and explains why reusable standard licences, or putting the data in the public domain are the best options for governments. While the report has a focus on government, many of the recommendations can also apply to public sector bodies as well as publishers of works more broadly.
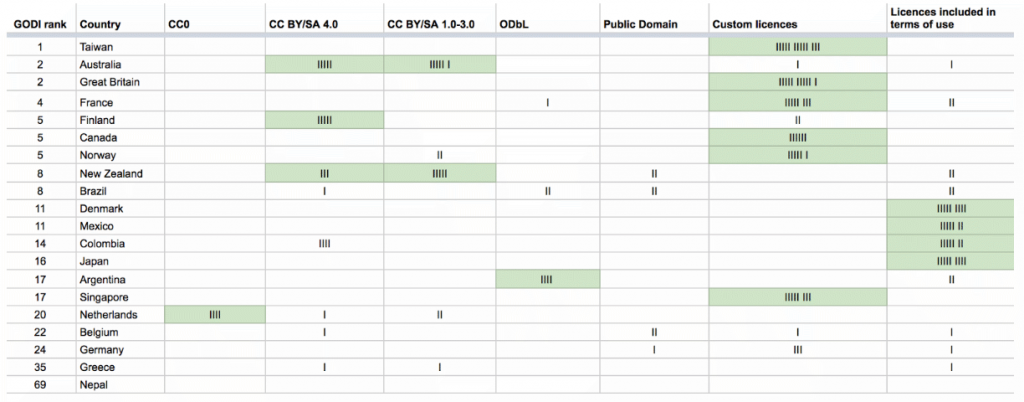
Licence proliferation continues to be a major challenge for open data. When licensors decide to create custom licences instead of using standard open licences, it creates a number of problems. Users of open data may find it difficult and cumbersome to understand all legal arrangements. More importantly though, legal uncertainties and compatibility issues with many different licenses can have chilling effects on the reuse of data.
This can create ‘data use silos’, a situation where users are legally allowed to only combine some data with one another, as most data would be legally impossible to use under the same terms. The ever-growing complexity of our licensing landscape may support such silos – counteracting efforts like the European Digital Single Market strategy, preventing the free flow of (public sector) information and impeding the growth of data economies. Standardised licences can smoothen this process by clearly stating usage rights.
Our latest report ‘Avoiding data use silos – How governments can simplify the open licensing landscape’ explains why reusable standard licences, or putting the data in the public domain are the best options for governments.

A lack of centralised coordination within governments is a key driver of licence proliferation. Different phases along the licensing process influence government choices what open licences to apply – including clearance of copyright, policy development, and the development and application of individual licences.
Our report outlines how governments can harmonise the decision-making around open licences and ensure their compatibility. We hope it will provide the ground for a renewed discussion around what good open licensing means – and inspire follow-up research on specific blockages of open licensing.
Governments who wish to make their public sector information as reusable as possible should consider following best practices and recommendations:
- Publish clear notices that concisely inform users about their rights to reuse, combine and distribute information, in case data is exempt from copyright or similar rights.
- Align licence policies via inter-ministerial committees and collaborations with representative bodies for lower administrative levels. Consider appointing an agency overseeing and reviewing licensing decisions.
- Precisely define reusable standard licences in your policy tools. Clearly define a small number of highly compatible legal solutions. We recommend putting data into the public domain using Creative Commons Zero, or applying a standard open license like Creative Commons Attribution 4.0.
- If you still opt to use custom licences, carefully verify if provisions cause incompatibilities with other licences. Add compatibility statements explicitly naming the licences and licence versions compatible with a custom licence, and keep the licence text short, simple, and reader-friendly.
Danny Lämmerhirt works on the politics of data, sociology of quantification, metrics and policy, data ethnography, collaborative data, data governance, as well as data activism. You can follow his work on Twitter at @danlammerhirt. He was research coordinator at Open Knowledge Foundation.








I am not very knowledgeable of all these issues. My centre of interest is Official statistics when conforming to the Fundamental principles of official statistics as adopted by the UN General Assembly http://unstats.un.org/unsd/dnss/gp/fundprinciples.aspx.
With such a global agreement, I would guess that there could be preferred or best licence to be used by governments when opening their aggregated statistical data.
Any suggestion?
This report is useful and very comprehensive, but I’m puzzled by the following:
“Copyright may also apply differently depending on the type of public sector body. For example, in the United Kingdom, Crown Copyright applies to government agencies which have ‘Crown status’. Other public sector bodies that do not fall under Crown Copyright would possibly not be able to apply the same custom open licences that government bodies use. The Open Government Licence 2.0 and 3.0 address this issue by being applicable to rights beyond Crown Copyright.”
As far as I can see all versions of the OGL support normal copyright and database right as well as Crown Copyright. Version 1.0 was problematic for other reasons, but any public sector body in the UK could use it.
Some comments purely on the UK context:
The approach recommended in the report would make sense if we were developing policy on open government data from day one. However I think applying this approach in the UK now would be a retrograde step.
As near as I can tell the report categorises the Open Government Licence (OGL) as a “custom licence”, but it’s not – the OGL is too widely used for that. (There are certainly too many bespoke variations of the OGL floating around, however. We should work to discourage those.)
Following the approach in the report, the alternatives would be to adopt either CC0 or CC BY in place of the OGL.
CC0 may make sense for some basic data infrastructure where knowing the source doesn’t matter. But generally attribition is important for public sector data, because sourcing the data to a government body establishes that the data is authoritative. I think the report understates the importance of attribution for public sector data.
CC BY is an excellent licence. But the OGL is already explicitly compatible with CC BY – any dataset released under the OGL can be relicensed as CC BY. OGL is slightly more permissive than CC BY, so it’s difficult to see an argument for replacing OGL with CC BY because re-users would lose some rights.
Perhaps a better approach in the UK would be for public bodies to tell re-users more clearly that they are welcome to re-use the data under either OGL or CC BY?
Glad for your thoughtful comment :)
> But generally attribition is important for public sector data, because sourcing the data to a government body establishes that the data is authoritative.
I feel like this logic is a bit inverted. “Establishing the data as authoritative” is a _possible_ desire of the third party using the data. If this is a valuable property, they will cite it. If it’s not, then they won’t. (Maybe their use-case is a chatbot when that citation doesn’t fit their flow — I dunno.) The type of thinking that leads a gov publisher to impose the “establishing of the data as authoritative” on downstream users… well, that seems quite an overbearing and paternal perspective
No; my point is about the importance of attribution for end users.
Generally it’s reasonable to expect to know where data comes from if we’re placing reliance on it. This isn’t about public bodies imposing their own view about the authority of the data; it’s about ensuring that end users have the opportunity to make that judgement themselves.
The OGL (including the version used in Canada) in sufficiently flexible to allow for attribution outside the “flow” of an app etc.