
This text shows a real case of how the Open Data Editor (ODE) impacted the workflow of an organisation working to serve the public good.

City of Zagreb’s open data team works with the Open Data Editor.
Organisation: City of Zagreb – Information System and Technical Service (City Office)
Location: Zagreb, Croatia 🇭🇷
Knowledge Area: Public Administration
Type of Data: Infrastructure data (energy consumption, public buildings, tourism, city districts)
The City of Zagreb manages one of Croatia’s largest open data platforms, serving citizens, researchers, and businesses. Despite hosting high-value datasets, the city faces challenges in data interoperability and quality due to systems across 16 city offices and numerous city owned companies. The team aims to bridge these gaps using FAIR principles (Findable, Accessible, Interoperable, Reusable) but lacks dedicated data stewards and standardised workflows.
The Challenge
Problem
Zagreb’s open data ecosystem is fragmented:
- Many platforms: Data is massively available but scattered across systems like the central Open Data Portal, GeoPortal, and niche projects (e.g., ZG3D: 3D model of the City of Zagreb, Ecological Map, Energy info center), each with its own metadata and standards.
- Limited expertise: A small team oversees data governance for the entire city, with limited technical training among broader stakeholders.
- Metadata gaps: Published datasets often lack contextual metadata, reducing usability. For example, a 400,000-row dataset on public building energy consumption (2019–2024) had no resource details or field descriptions.
Impact
- Manual data cleaning and validation consume weeks of effort.
- Low reuse of datasets by external users (e.g., in 2020, an open framework for data valuation was used to investigate the state of the City’s open data infrastructure, and it showed that only 7,16% of open data platform potential was utilised).
- Missed opportunities for data-driven projects due to the inconsistent quality of published data.
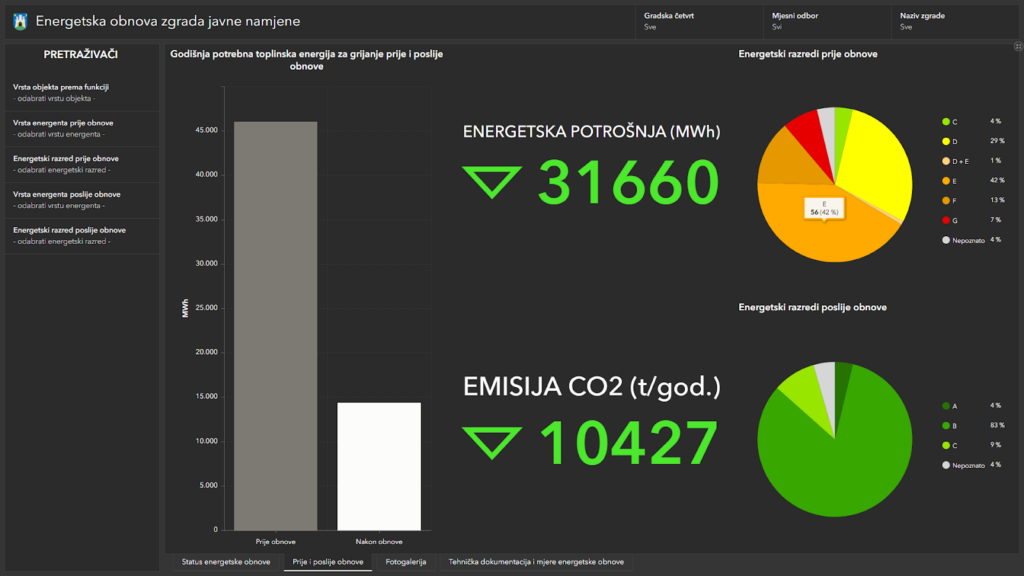
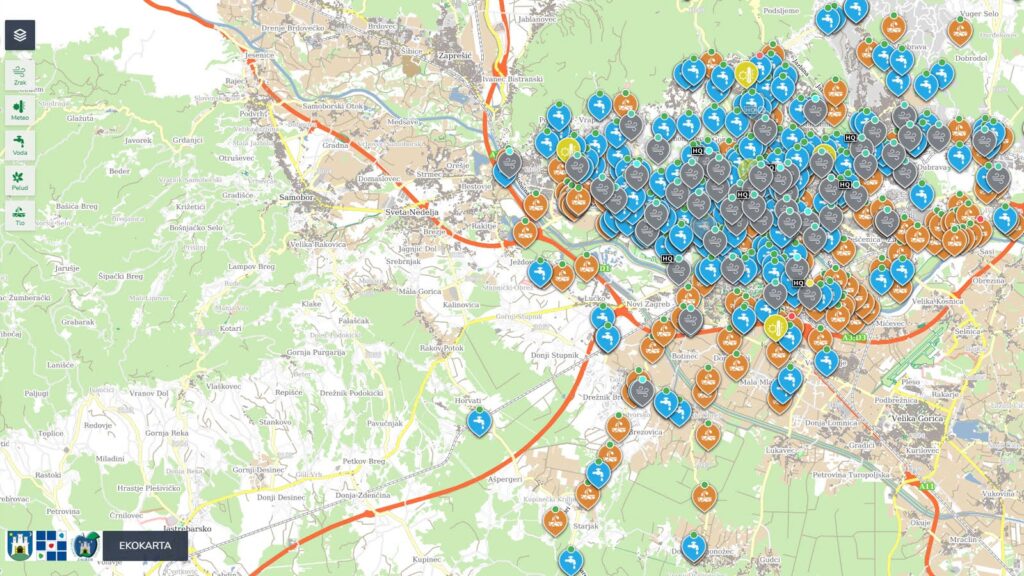
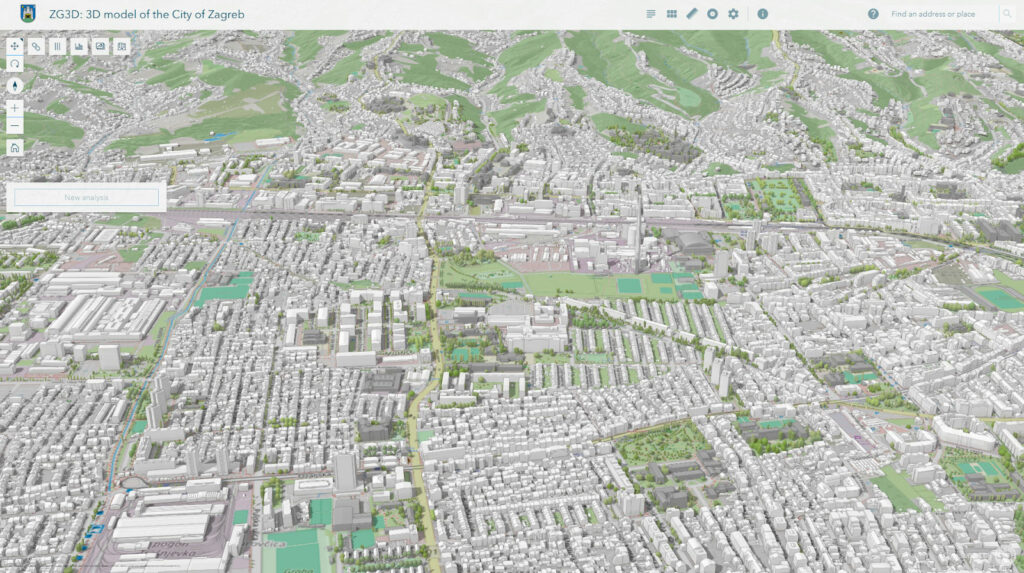
Examples of databases that the City of Zagreb feeds and maintains for public and open access.
The Solution
The City of Zagreb piloted Open Data Editor (ODE) to:
- Audit existing datasets: ODE flagged inconsistencies (e.g., missing values, formatting errors) in seconds, such as a public buildings dataset with 11 columns of unlabeled energy metrics.
- Enrich metadata: The team added critical context (e.g., data owners, sourcing methods) directly in ODE’s metadata panel, aligning with FAIR principles.
- Educate stakeholders: ODE’s visual interface helped non-technical staff understand data quality standards.
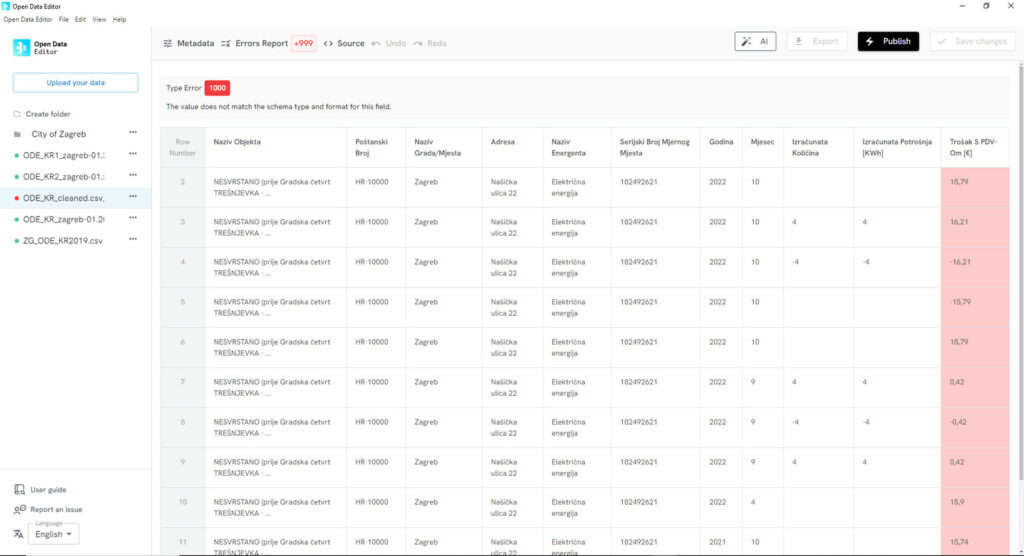
In this spreadsheet, ODE flagged 1,000 inconsistencies in seconds.
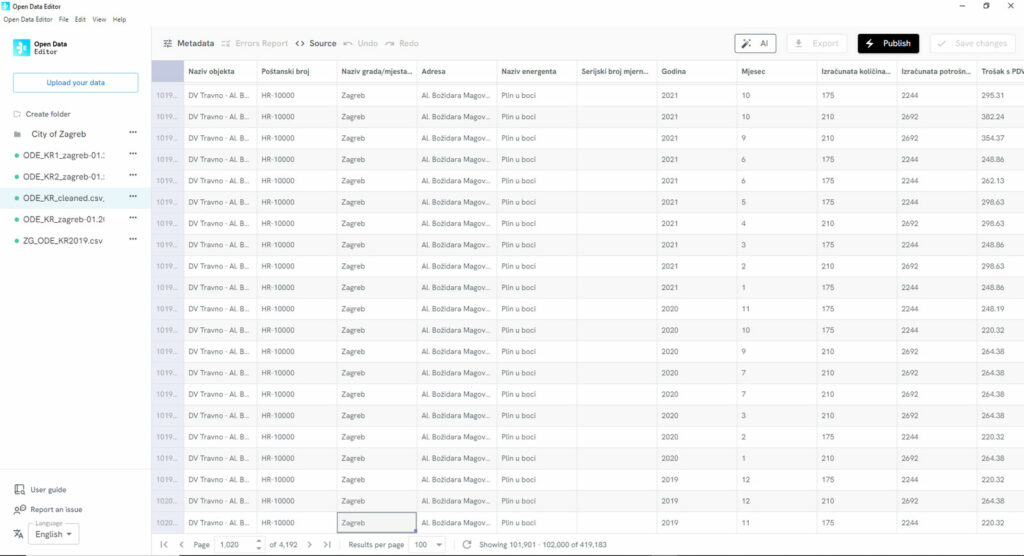
The list in the side menu shows the databases that have been cleaned following a scan by the Open Data Editor, and which are now guaranteed to be of high quality and compliant with open data standards.
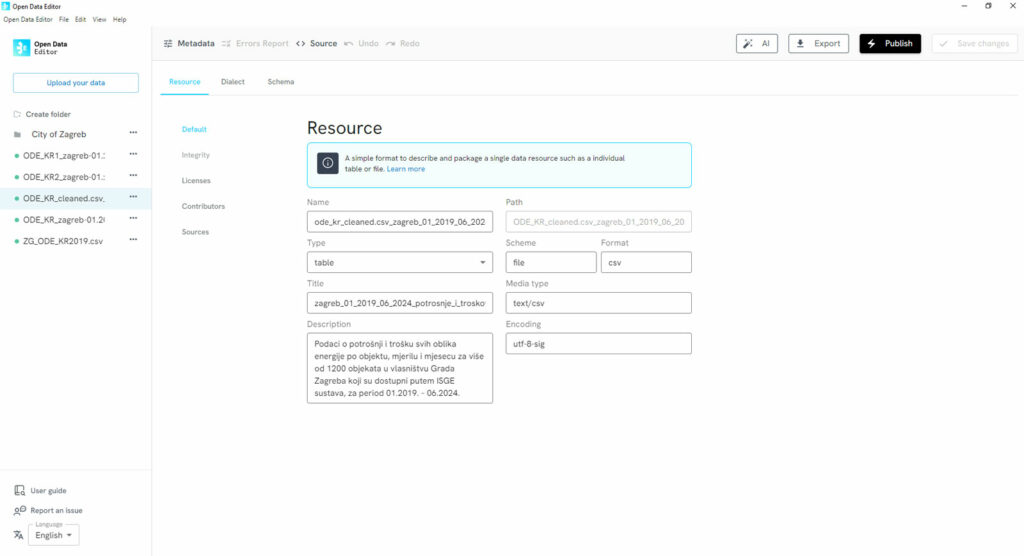
ODE’s metadata panel was central to understanding the importance of interoperability and creating a culture of data literacy in the public administration.
The Results
- Efficiency: Reduced error-resolution time from weeks to seconds.
- Improved usability: 5 pilot datasets now meet Frictionless Data standards, with complete metadata.
- Capacity building: The team uses ODE to train other city offices, fostering a culture of data literacy.
- Hackathon-ready data: Cleaned datasets enabled projects like a kindergarten locator tool and upcoming hackathons.
Quote

Kristian Ravic, Senior Advisor
“ODE revealed how far we were from FAIR principles—it wasn’t just about fixing cells but understanding why data needs context. For the first time, we have a tool that helps our team and the entire City administration speak the same data language. The energy dataset we cleaned is now a model for future publications, proving open data’s potential when quality is prioritised.”
About the Open Data Editor

The Open Data Editor (ODE) is Open Knowledge’s new open source desktop application for nonprofits, data journalists, activists, and public servants, aiming at helping them detect errors in their datasets. It’s a free, open-source tool designed for people working with tabular data (Excel, Google Sheets, CSV) who don’t know how to code or don’t have the programming skills to automatise the data exploration process.
Simple, lightweight, privacy-friendly, and built for real-world challenges like offline work and low-resource settings, ODE is part of Open Knowledge’s initiative The Tech We Want — our ambitious effort to reimagine how technology is built and used.
And there’s more! ODE comes with a free online course that can help you improve the quality of your datasets, therefore making your life/work easier.
Download Open Data Editor 1.4.0 using the following buttons:
↪️ Take the course: Learn how to use ODE
All of Open Knowledge’s work with the Open Data Editor is made possible thanks to a charitable grant from the Patrick J. McGovern Foundation. Learn more about its funding programmes here.







