The following guest post is by Guillermo Moncecchi.

In a previous post, we advocated for the generation of a Public Digital Infrastructure (PDI), suggesting that governments should advance in the provision of open digital capabilities, free of restrictions, to do, within the law, whatever we want with them. These capabilities would be built on top of a national physical infrastructure and include data, services, software and knowledge.
A lot has been written in the last couple of years about open data. An large number of advocates and an increasing government commitment (mostly related to transparency, but also approaching infrastructure provisioning) suggest a promising future for open data. Probably, ten years from today, the term “open data” will no longer be used. “Closed government data” will be the main related concern, because public data will be globally open, by default.
On the road to Public Digital Infrastructure development, we propose going one step further from open data. We must move on to Open Government Services.

The Open Government Service definition we are proposing is slightly different from the one of Open Software Service from OKFN. While Open Software Services aim to be the “open source” version of online services, Open Government Services are more the service-version of Open Data: online services for exposing data and performing computation, without access restrictions and verifiable results.
Let us introduce a motivating example. At Montevideo, the bus timetable data is open. You can check, for each bus line, the departure and arrival times at certain checkpoints (the little watches in the following picture). In the software we developed for final users, we additionally estimate the scheduled time for each intermediate bus stop between checkpoints, calculating it using a rule of three simple. If somebody wants to develop a similar system, she should download our open data and implement the interpolation rule. Not too difficult.
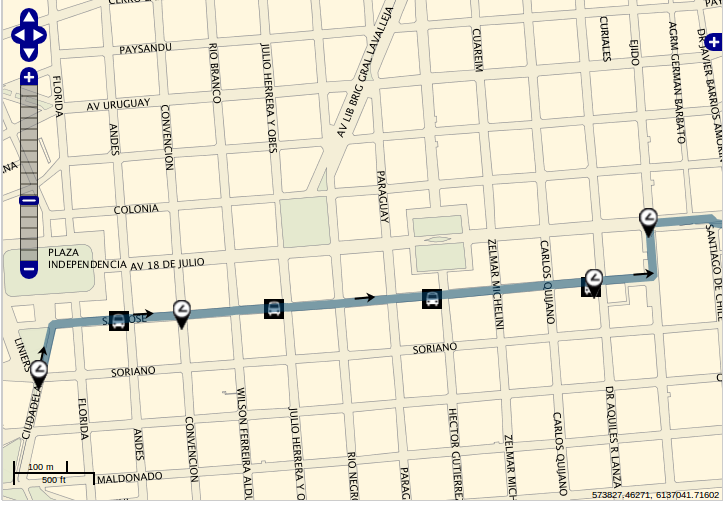
But, if you look at the problem from a developer’s point of view, something looks suboptimal. Why do you have to download the data? And, more important, why replicate an algorithm somebody already developed? If we, as the city, published an open service that, given a line and a bus stop, returned the (estimated) scheduled time, it would be much easier to develop an application for the Montevideo’s citizens (something that is, after all, the reason for freeing our data). In fact, this is exactly what is starting to happen. After we based our “A qué hora pasa?” web application on RESTful services (even when we did not even publish its specification), a third-party application started to use them, and we know some others are on the go.
There are some additional features of data that make Open Services not only convenient, but also necessary:
- Real-time data: this is information delivered immediately after collection. Consider, for example, the Transport for London Live Bus Arrivals. The Open Data approach is not plausible: one of the most important features of these data is its availability right now. In fact, the London transport website includes a “Developers Section” that provides services for checking arrival times.
- Big data: I take “big data” as the opposite of small data: the amount of data you cannot conveniently store and process on a single high-end laptop or server. Open data is supposed to make things easier for people; if you need a supercomputer to analyze open data, then it is not open anymore. In this case, open services would allow the user to refine her queries and get the data she is interested in. A good example is the huge data section of the National Climatic Data Center; if it wasn’t for their services, data access would be almost impossible.
As you can see, there are already many examples of services on open data. However, we should start thinking not just about services on open data, but directly about open services. Emulating what has been done for Open Data, we suggest the following principles for Open Services:
- Open Services should be based on open data. Open Services should never substitute Open Data. I repeat, never. They are intended to make things easier, not for preventing access.
- Open Services should be verifiable. Since Open Services include Open Data and algorithms, we need a way to check results are what we expect, and are not being modified during processing. The most obvious way to comply with this is to publish the algorithms and processes besides the data (in our bus timetable, the interpolation algorithm). But there could be other forms of verifiability: in the real-time bus data, we can simply check if the bus is where the service says, just by going to the real place.
- Open Services should be open for everybody, with no limitations, except for security reasons. No registration, no justification. Exactly the same principle we applied to open data.
- Open Services should be accessible through Open Standards, which no entity has exclusive control (*).
Governments are opening our data. Governments are opening our code. Now it is time for opening our code applied to our data. It is time for Open Services.
(*) I am tempted to add: “and using RESTful services!”, but the Semantic Web people would not be happy, and I have friends there.

Guillermo Moncecchi is Head of Development in the IT department of the city of Montevideo. He is also part of the Institute of Computer Science at the Universidad de la República, where he works on Natural Language Processing.
Image credit: bus stop by Vince Alongi. CC-BY
This post is by a guest poster. If you would like to write something for the Open Knowledge Foundation blog, please see the submissions page.








Description above it looks like a superset of the OSSD, applied specifically to government data services. OSSD basically says all software providing the service needs to be open source (per the Open Software Definition) and data/content provided by the service needs to be open knowledge (per the Open Definition).
Compare that to what I take to be a draft Open Government Service definition at the end of this post:
“based on” is vague, but I assume this just means data provided by the service needs to be open.
Part of verifiability concerns the service, which is same as OSSD — software running the service is open source.
Verifiability/reproducibility of data is something additional, which I think ought to be thought of with respect to the data, rather than a service. There’s open data (compliant with the Open Definition), then there’s verifiable open data.
This is probably beyond open data, at least as specified by the Open Definition, which doesn’t specify anything about registration, but does allow for some friction “at no more than a reasonable reproduction cost” (though “preferably downloading via the Internet without charge”).
If the data is open — see point 4 of http://opendefinition.org/okd/ — and the service providing the access is open source, this seems to be covered.
Why Open Government Service rather than Open Data Service? I think we should be wary of whitewashing open government as only having to do with data and [e]services rather than accountability and the like to which open data is a mere helper. Furthermore, we should also demand openness from other organizations.
Excepting previous paragraph, I see little harm and some benefit in additional open X definitions and principles so long as they don’t sanction practices that would actually be not compliant with the Open Source Definition or Open Definition.