Introduction
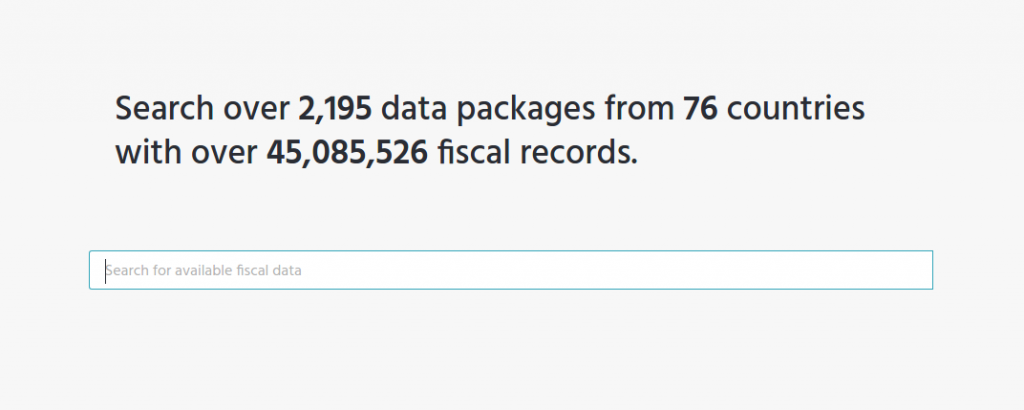
OpenSpending is a free, open and global platform to search, visualise, and analyse fiscal data in the public sphere. This week, we soft launched an updated technical platform, with a newly designed landing page. Until now dubbed “OpenSpending Next”, this is a completely new iteration on the previous version of OpenSpending, which has been in use since 2011.
At the core of the updated platform is Fiscal Data Package. This is an open specification for describing and modelling fiscal data, and has been developed in collaboration with GIFT. Fiscal Data Package affords a flexible approach to standardising fiscal data, minimising constraints on publishers and source data via a modelling concept, and enabling progressive enhancement of data description over time. We’ll discuss in more detail below.
From today:
- Publishers can get started publishing fiscal data with the interactive Packager, and explore the possibilities of the platform’s rich API, advanced visualisations, and options for integration.
- Hackers can work on a modern stack designed to liberate fiscal data for good! Start with the docs, chat with us, or just start hacking.
- Civil society can access a powerful suite of visualisation and analysis tools, running on top of a huge database of open fiscal data. Discover facts, generate insights, and develop stories. Talk with us to get started.
All the work that went into this new version of OpenSpending was only made possible by our funders along the way. We want to thank Hewlett, Adessium, GIFT, and the OpenBudgets.eu consortium for helping fund this work.
As this is now completely public, replacing the old OpenSpending platform, we do expect some bugs and issues. If you see anything, please help us by opening a ticket on our issue tracker.
Features
The updated platform has been designed primarily around the concept of centralised data, decentralised views: we aim to create a large, and comprehensive, database of fiscal data, and provide various ways to access that data for others to build localised, context-specific applications on top. The major features of relevance to this approach are described below.
Fiscal Data Package
As mentioned above, Fiscal Data Package affords a flexible approach to standardising fiscal data. Fiscal Data Package is not a prescriptive standard, and imposes no strict requirements on source data files.
Instead, users “map” source data columns to “fiscal concepts”, such as amount, date, functional classification, and so on, so that systems that implement Fiscal Data Package can process a wide variety of sources without requiring change to the source data formats directly.
A minimal Fiscal Data Package only requires mapping an amount and a date concept. There are a range of additional concepts that make fiscal data usable and useful, and we encourage the mapping of these, but do not require them for a valid package.
Based on this general approach to specifying fiscal data with Fiscal Data Package, the updated OpenSpending likewise imposes no strict requirements on naming of columns, or the presence of columns, in the source data. Instead, users (of the graphical user interface, and also of the application programming interfaces) can provide any source data, and iteratively create a model on top of that data that declares the fiscal measures and dimensions.
GUIs
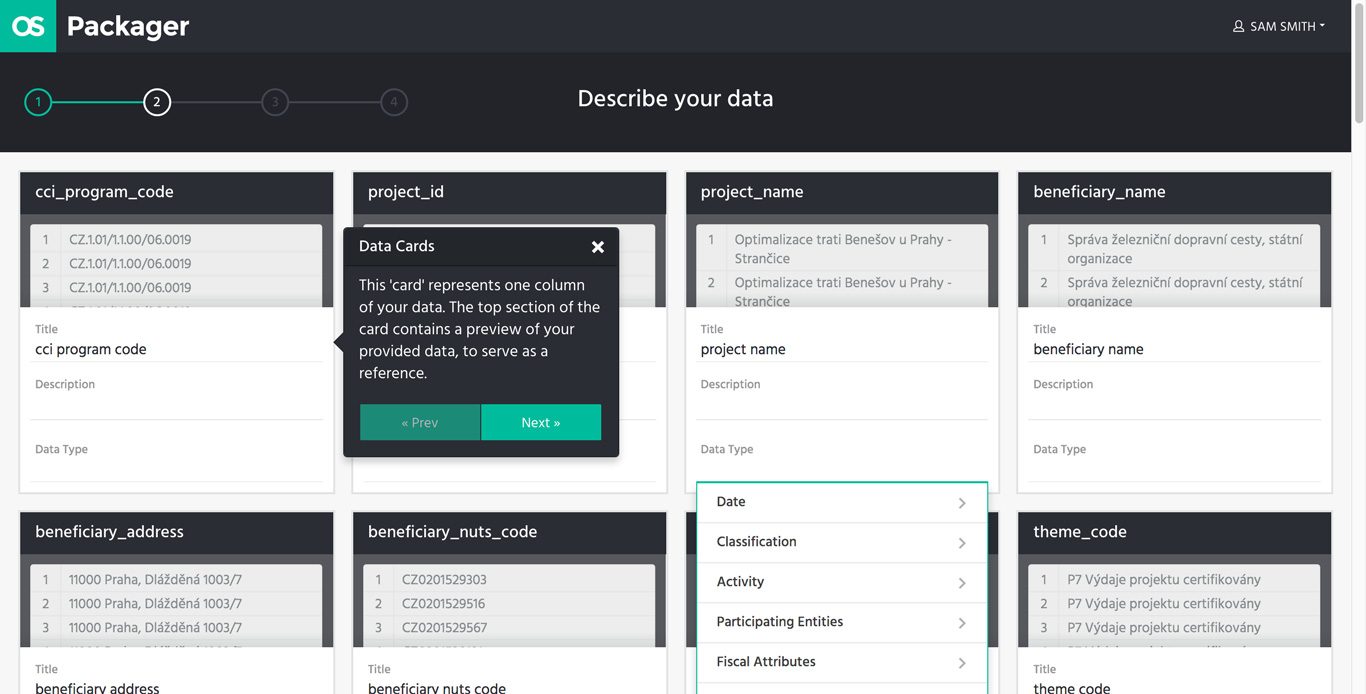
Packager
The Packager is the user-facing app that is used to model source data into Fiscal Data Packages. Using the Packager, users first get structural and schematic validation of the source files, ensuring that data to enter the platform is validly formed, and then they can model the fiscal concepts in the file, in order to publish the data. After initial modelling of data, users can also remodel their data sources for a progressive enhancement approach to improving data added to the platform.
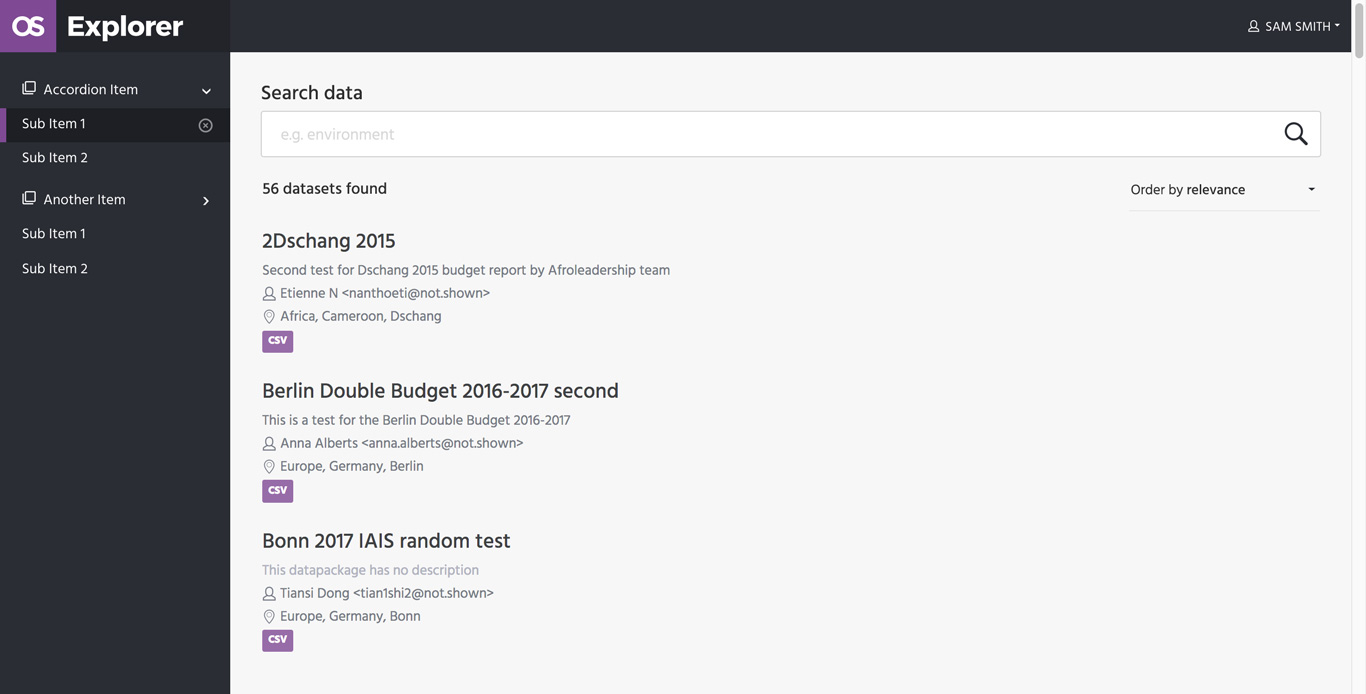
Explorer
The Explorer is the user-facing app for exploration and discovery of data available on the platform.
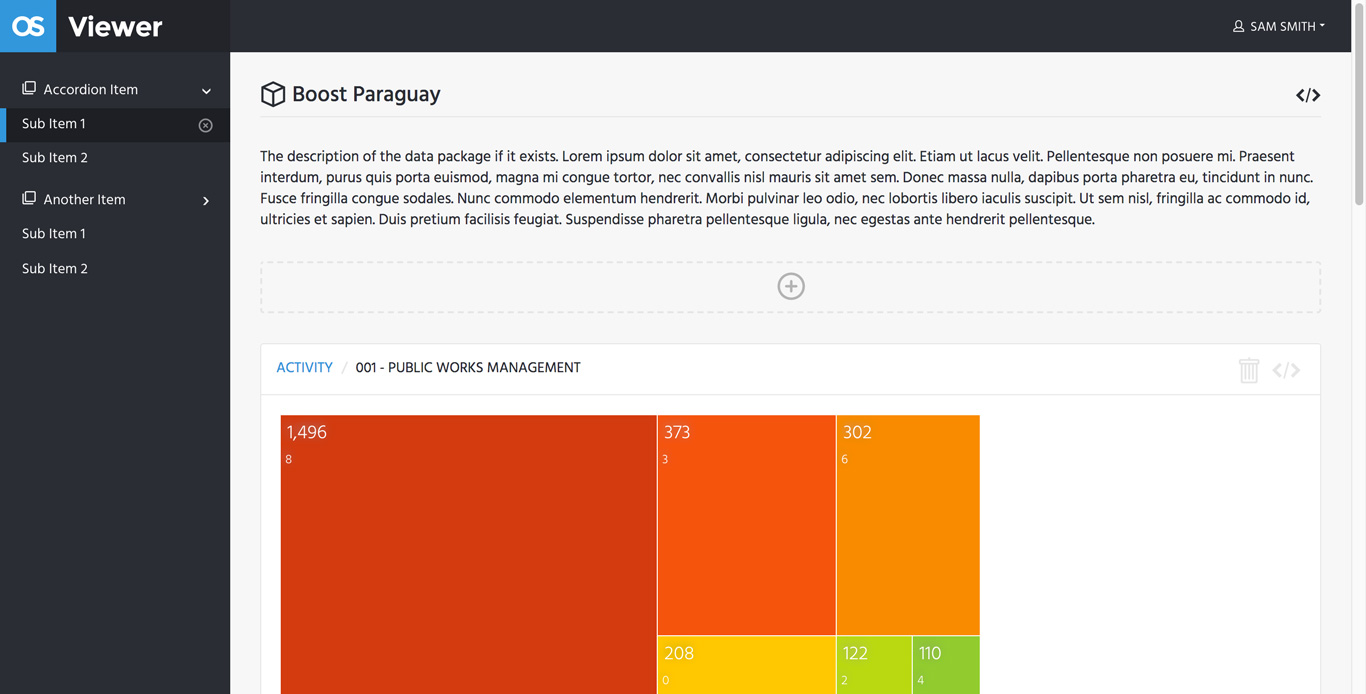
Viewer
The Viewer is the user-facing app for building visualisations around a dataset, with a range of options, for presentation, and embedding views into 3rd party websites.
DataMine
The DataMine is a custom query interface powered by Re:dash for deep investigative work over the database. We’ve included the DataMine as part of the suite of applications as it has proved incredibly useful when working in conjunction with data journalists and domain experts, and also for doing quick prototype views on the data, without the limits of API access, as one can use SQL directly.
APIs
Datastore
The Datastore is a flat file datastore with source data stored in Fiscal Data Packages, providing direct access to the raw data. All other databases are built from this raw data storage, providing us with a clear mechanism for progressively enhancing the database as a whole, as well as building on this to provide such features directly to users.
Analytics and Search
The Analytics API provides a rich query interface for datasets, and the search API provides exploration and discovery capabilities across the entire database. At present, search only goes over metadata, but we have plans to iterate towards full search over all fiscal data lines.
Data Importers
Data Importers are based on a generic data pipelining framework developed at Open Knowledge International called Data Package Pipelines. Data Importers enable us to do automated ETL to get new data into OpenSpending, including the ability to update data from the source at specified intervals.
We see Data Importers as key functionality of the updated platform, allowing OpenSpending to grow well beyond the one thousand plus datasets that have been uploaded manually over the last five or so years, towards tens of thousands of datasets. A great example of how we’ve put Data Importers to use is in the EU Structural Funds data that is part of the Subsidy Stories project.
Iterations
It is slightly misleading to announce the launch today, when we’ve in fact been using and iterating on OpenSpending Next for almost 2 years. Some highlights from that process that have led to the platform we have today are as follows.
SubsidyStories.eu with Adessium
Adessium provided Open Knowledge International with funding towards fiscal transparency in Europe, which enabled us to build out significant parts of the technical platform, commision work with J++ on Agricultural Subsidies , and, engage in a productive collaboration with Open Knowledge Germany on what became SubsidyStories.eu, which even led to another initiative from Open Knowledge Germany called The Story Hunt.
This work directly contributed to the technical platform by providing an excellent use case for the processing of a large, messy amount of source data into a normalised database for analysis, and doing so while maintaining data provenance and the reproducibility of the process. There is much to do in streamlining this workflow, but the benefits, in terms of new use cases for the data, are extensive.
We are particularly excited by this work, and the potential to continue in this direction, by building out a deep, open database as a potential tool for investigation and telling stories with data.
OpenBudgets.eu via Horizon 2020
As part of the OpenBudgets.eu consortium, we were able to both build out parts of the technical platform, and have a live use case for the modularity of the general architecture we followed. A number of components from the core OpenSpending platform have been deployed into the OpenBudgets.eu platform with little to no modification, and the analytical API from OpenSpending was directly ported to run on top of a triple store implementation of the OpenBudgets.eu data model.
An excellent outcome of this project has been the close and fruitful work with both Open Knowledge Germany and Open Knowledge Greece on technical, community, and journalistic opportunities around OpenSpending, and we plan for continuing such collaborations in the future.
Work on Fiscal Data Package with GIFT
Over three phases of work since 2015 (the third phase is currently running), we’ve been developing Fiscal Data Package as a specification to publish fiscal data against. Over this time, we’ve done extensive testing of the specification against a wide variety of data in the wild, and we are iterating towards a v1 release of the specification later this year.
We’ve also been piloting the specification, and OpenSpending, with national governments. This has enabled extensive testing of both the manual modeling of data to the specification using the OpenSpending Packager, and automated ETL of data into the platform using the Data Package Pipelines framework.
This work has provided the opportunity for direct use by governments of a platform we initially designed with civil society and civic tech actors in mind. We’ve identified difficulties and opportunities in this arena at both the implementation and the specification level, and we look forward to continuing this work and solving use cases for users inside government.
Credits
Many people have been involved in building the updated technical platform. Work started back in 2014 with an initial architectural vision articulated by our peers Tryggvi Björgvinsson and Rufus Pollock. The initial vision was adapted and iterated on by Adam Kariv (Technical Lead) and Sam Smith (UI/X), with Levko Kravets, Vitor Baptista, and Paul Walsh. We reused and enhanced code from Friedrich Lindenberg. Lazaros Ioannidis and Steve Bennett made important contributions to the code and the specification respectively. Diana Krebs, Cecile Le Guen, Vitoria Vlad and Anna Alberts have all contributed with project management, and feature and design input.
What’s next?
There is always more work to do. In terms of technical work, we have a long list of enhancements.
However, while the work we’ve done in the last years has been very collaborative with our specific partners, and always towards identified use cases and user stories in the partnerships we’ve been engaged in, it has not, in general, been community facing. In fact, a noted lack of community engagement goes back to before we started on the new platform we are launching today. This has to change, and it will be an important focus moving forward. Please drop by at our forum for any feedback, questions, and comments.
Paul is the CEO at Datopian







