



Some months ago we started looking at how we might possibly use an RDF store instead of a SQL database behind data-driven websites — of which OKF has several. The reasons have to do with making the data reuseable in a better way than ad-hoc JSON APIs.
As we tend to program in Python and use the Pylons framework_static/write-ops.png this led us to consider some alternatives like RDFAlchemy and SuRF. Both of those build on top of RDFLib and try to present a programming interface reminiscent of SQL-ORM middleware like SQLObject and SQLAlchemy. They assume a single database-like storage for the RDF data and in some cases make some assumptions about the form of the data itself.
One important thing that they do not directly handle is customised indexing — and triplestores vary widely in terms of how well certain types of queries will perform, if they are supported at all. Overall, using RDFAlchemy or SuRF didn’t seem like much of a gain over using RDFLib directly. So we started writing our own middleware which we’ve named ORDF (OKFN RDF Library).
Code and documentation is at http://ordf.org/
ORDF Features and Structure
Key features of ORDF:
- Open-source and python-based (builds on RDFLib)
- Clean separation of functionality such as storage, indexing, web frontend
- Easy pluggability of different storage and indexing engines (all those supported by RDFLib, 4store, simple-disk using pairtree etc)
- Extensibility via messaging (we use rabbitmq)
- Built-in rdf “revisioning”: every set of changes to the RDF store is kept in a “changeset”. This enables provenance, roll-back, change reporting “out-of-the-box”
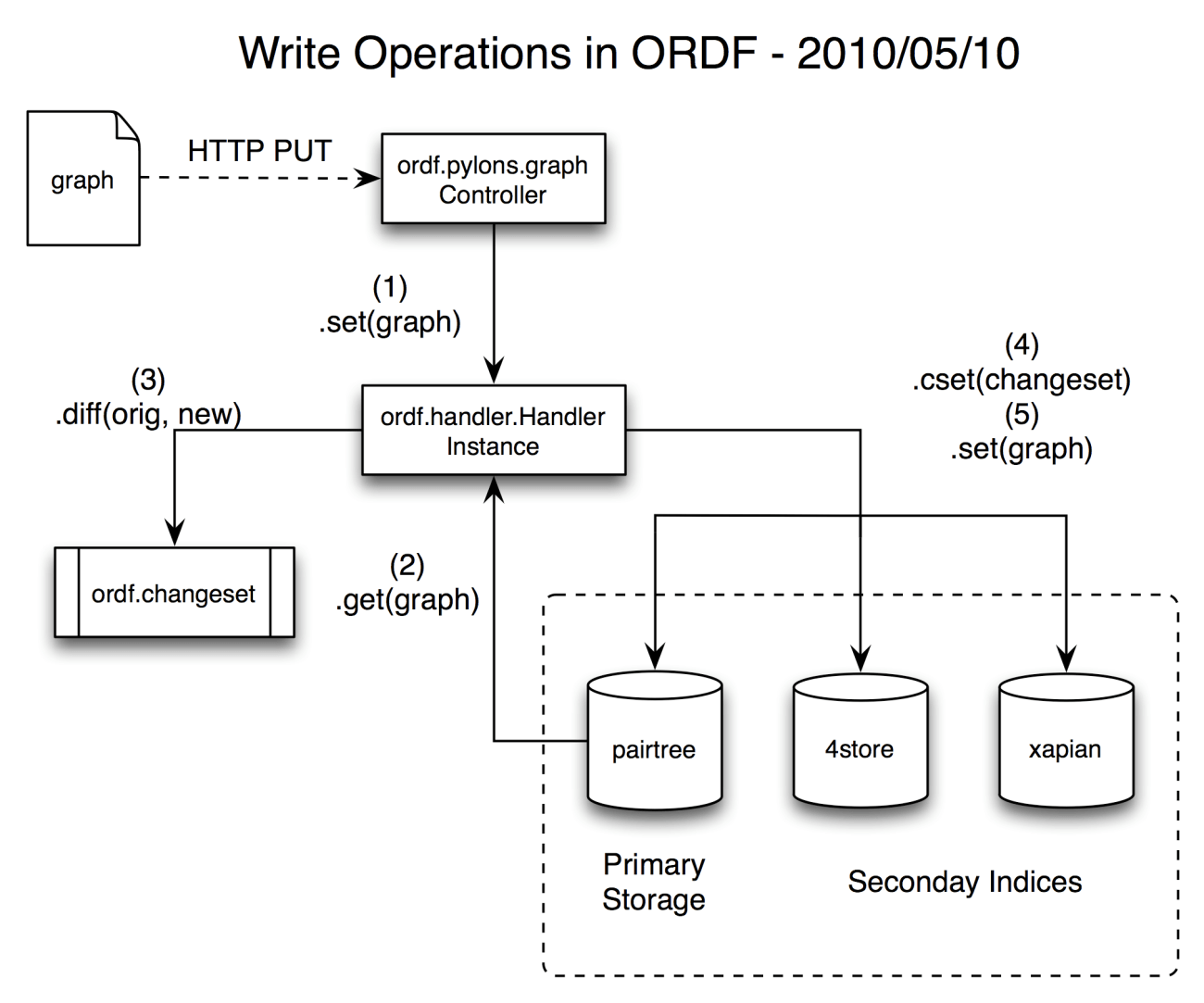
To illustrate how this works, here’s a diagram showing a write operation in ORDF using most of the features described above. Below we go into detail describing how it all works.
Forward Compatibility with RDFLib
The ORDF middleware solves several problems. The first, and most mundane, is to paper over the significant API changes between versions 2.4.2 and 3.0.0 of RDFLib. The RDFLib moved things around a bunch and this tends to break things because statements like from rdflib import Graph need to be changed to from rdflib.graph import Graph. So the first thing ORDF does is let you do from ordf.graph import Graph which will work no matter which version of RDFLib you have installed. This is important because the changes in 3.0.0 are deeper than just some renaming of modules, there is software, the FuXi reasoner and anything that uses the SPARQL query language, that will not work well with the new version. This means that we basically have a forward compatibility layer that means that software developed with ORDF should continue to work once newer RDFLib stabilises.
Pylons Support
Only slightly less mundane than the previous, ORDF includes some code that should be common amongst web applications using the Pylons framework for accessing the ORDF facilities. This means controllers for obtaining copies of graphs in various serialisations and for implementing a SPARQL endpoint.
Indices and Message Queues
Then we have indexes and queueing. Named graphs, the moral equivalent of the objects from the SQL-ORM world are stored in more than one place to facilitate different kinds of queries,
- The pairtree filesystem index, which is good for retrieving a graph if you know its name and simply stores it as a file in a specialised directory hierarchy on the disk. This is not good for querying but is pretty much future-proof — at least as long as it is possible to read a file from the disk.
- An rdflib supported storage, suitable for small to medium sized datasets, does not depend on any external software and allows SPARQL queries over the data for graph traversal operations
- The 4store quad-store which fulfills a similar role for larger datasets, allowing SPARQL queries but requires an additional piece of software running (possibly on a cluster for very large datasets) and is somewhat harder to set up.
- A xapian full-text search index, allows free-form queries over text strings, something that no triplestore does very well.
There are plans for further storage back-ends, specifically using Solr as well as other triplestores such as Jena and Virtuoso.
A key element of this indexing architecture is that it is distributed. Whilst you can configure all of these index types into a single running program — and it is common to do so for development — in reality some indexing operations are expensive and you don’t necessarily want the client program sitting and waiting while they are done synchronously. So there is also a pseudo-index that sends graphs to a rabbitmq messaging server and for each index a daemon is run that listens to a queue on a fan-out exchange.
Introducing a layer of message queueing also makes it possible to support inferencing or the process of deriving new information or statements from the given data. This is an operation that is considerably more computationally expensive than mere indexing. It is accomplished by using two queues. When a graph is save, it first gets put on a queue conventionally called reason. The FuXi reasoner listens to that queue, computes some new statements (known in the literature as a production rule or forward-chaining system), and then puts the resulting, augmented, graph onto a queue called index and thence to the indexers.
Ontology Logic
Until most recently there was only one ontology-specific behaviour coded into ORDF and that was the ChangeSet. It is still important. It provides low level, per-statement, provenance and change history information. This is built into the system. A save operation on a graph is accomplished by obtaining a change context and adding one or more graphs to it, then committing the changes. Before sending the graphs out for indexing or reasoning or queueing or whatnot, a copy of the previous version of the graphs is obtained (usually from pairtree storage) and the differences are calculated. These differences along with some metadata make up the ChangeSet which is saved and indexed along with the graphs themselves. This accomplishes what we call Syntactic Provenance because it operates at the level of individual statements.
Lately several more modules have been added to support other vocabularies. The work on the Bibliographica project led to the introduction of the OPMV vocabulary for Semantic Provenance. This is used to describe the way a data record from an external source (in this case MARC data) is transformed by a Process into a collection of statements or graph, and the way other graphs are derived from this first one. This is a distinct problem from Syntactic Provenance since it deals with the relationships between entities or objects and not simply add/remove operations on their attributes.
Another addition has been the ORE Aggregation vocabulary which is also used in Bibliographica. In our system since distinct entities or objects are stored as named graphs, we want to avoid having data duplicated in places where it should not be. For example, a book might have an author and users are ultimately interested in seeing the author’s name when they are looking at data about the book. But we do not want to store the author’s details in the book’s graph because that means that if someone notices and corrects an error the error must be corrected both in the author’s graph and their book’s. Better to keep such changes in one place. So what we actually do is create an aggregation. The aggregation contains (points at, aggregates) the book and author graph and also includes a pointer to some information on how to display it.
More to come on concrete implementation of ontology-specific behaviour, MARC processing and Aggregations in a following-up post on Bibliographica.
Next Steps
There is much more ontology-specific work to be done. First on the list is an implementation in Python of the Fresnel vocabulary that is used to describe how to display RDF data in HTML. It is more a set of instructions than a templating language and we have already written an implementation in JavaScript. It is crucial, however, that websites built with ORDF do not rely on JavaScript for presentation and we should rely on custom templates as little as possible.
ORDF is now stable enough to start using in other projects, at least within the OKF family. A first and fairly easy case will be updating the RDF interface to CKAN to use it — fitting as ORDF actually started out as a refactor of that very codebase.
1 Comment