Recently, a small team gathered in Berlin for the School of Data kick-off sprint. After three days fueled by coffee, felt-tip pens and a multi-coloured array of post-it-notes, the sprint left us with a true appreciation of the amazing community we are working with, and an exciting new structure to underpin the School of Data. Read on for more details, and to find out how you can get involved…

As we have stated in previous blog posts, the purpose of the School of Data is:
“to provide online training for data ‘wrangling’ skills – that is, the ability to find, retrieve, clean, manipulate, analyze and represent different types of data.”
Excellent. But what exactly does that mean? What basic competencies allow those abilities to be developed? How are they best taught? And is it possible to run a School of Data which caters both for those with no technical skills, and for those who already have significant data expertise?
In Berlin, we gathered a small team of project leaders and community experts from the Open Knowledge Foundation, P2PU and the Tactical Technology Collective, and mixed them with some leading data wranglers to address these and many other questions. For one adrenalin-fueled afternoon, around 40 community members also joined us online for a virtual sprint to test our ideas and contribute their own. A huge thanks to everyone who joined in – the afternoon was productive and hugely inspiring! Three days later and we had answered some questions, raised several more, and, most excitingly, had a framework to support the School of Data. This framework is outlined below.
The Data Pipeline
In our discussions, we quickly established that data wrangling takes place in several stages; in order to process data, it must be moved through a ‘pipeline’. The basic stages of the pipeline are outlined in the diagram below.
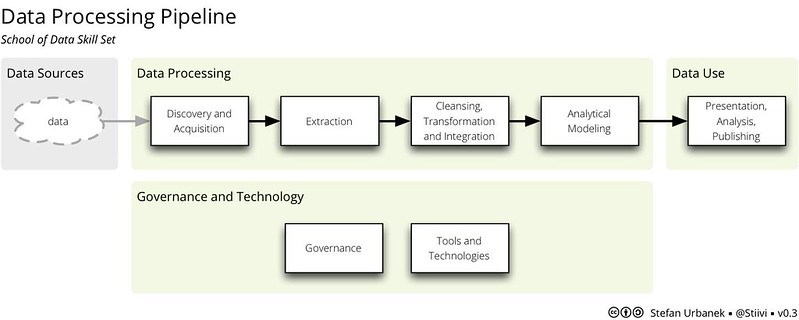
Raw data must usually travel through every stage of the pipeline – sometimes going through one stage more than once. However, several different data wranglers could be involved. For example, a civil servant may collect, process and present some data in a basic table; someone from a civil society organisation may then find, clean and analyse that data for their own needs; and finally, they may pass it on to a data visualisation expert or journalist to help them build a story for the public.

To fully understand data, wranglers need to be familiar with every stage of the pipeline, but, depending on their interests, some may want to hone their skills at one specific stage.
The School of Data will cater for both models by offering a combination of learning ‘journeys’ – in which learners will travel the data pipeline from start to finish – and ‘plunges’ – which will look at one specific area in more depth.
The Skills Map
Once the pipeline was in place, the challenge was to identify the skills that are needed along each step of the way. Cue many more post-it-notes!

At every stage of the data pipeline, a variety of skills could be employed to wrangle data. The appropriate technique usually depends on the nature of the data itself and exactly what you want to do with it. The abilities of the data wrangler will also play a part in which skills are deployed – some techniques are more technical than others!
With the excellent guidance of Stefan Urbanek, our posters and post-it-notes were transformed into the following skills map.
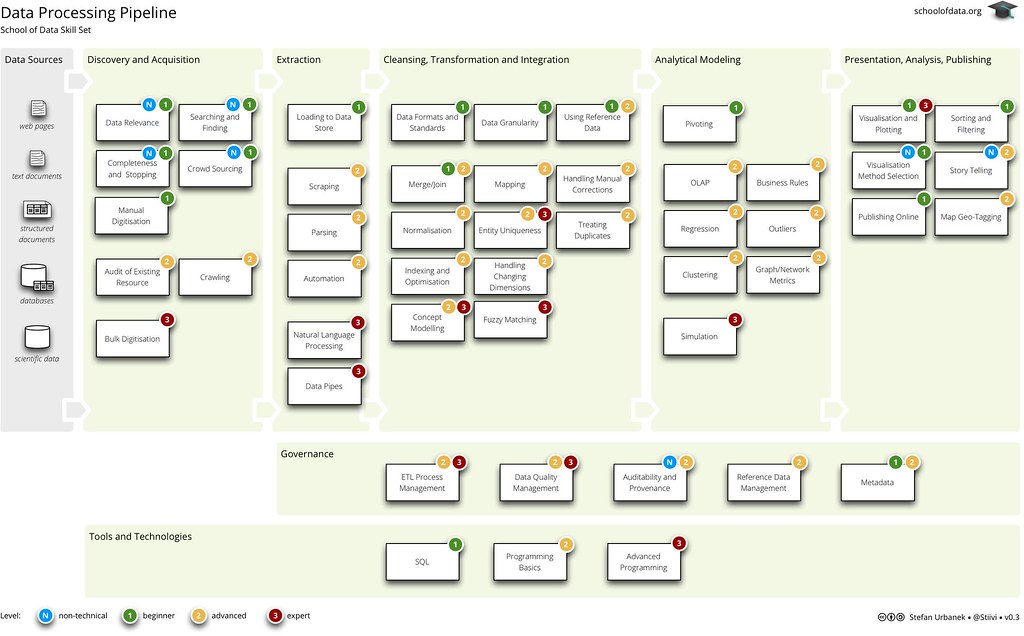
The map shows the level of prior-knowledge required in order to develop various skills. ‘N’ indicates that no technical knowledge is necessary, whilst levels 1, 2 and 3 become gradually more advanced. For level 3, prior programming ability is likely to be necessary.
Learners at the School of Data should assess their knowledge and gauge which challenges are appropriate. In time, guidelines will be added to help you work this out. Generally, common sense applies – absolute beginners shouldn’t attempt a level 3 course on fuzzy matching, whereas someone with a lot of experience may want to skip through a level 1 class on pivoting and get straight on to data simulation.
This is the moment for a dose of realism: the School of Data won’t be able to address all of these skills in its first iteration! Neither is this list exhaustive, and we welcome your feedback and, most of all, your input. See below for more on how to comment and get involved.
So what now?

Many of you have been asking great questions about the School of Data. We have tried to answer some of these in our new, expanded list of Frequently Asked Questions – take a look!
One of the key questions has been about the timeline for the School of Data. We expect to launch the first iteration of the School during Autumn 2012. Another question has been about how you can help us! The enthusiasm during the virtual sprint was inspiring, and the energy of the emerging School of Data community is one of the most exciting aspects of the School of Data to date. Below, we have outlined in more details how you can get involved…
Get Involved!
The first learning challenges at the School of Data are going to be produced internally, to ensure that we cover a good balance of the basic skills from the outset.
Whilst we are creating and curating this content, we would appreciate your help in a number of ways:
- Add content to the Data Wrangling Handbook! In some ways this is the key task at present. The Data Wrangling Handbook will function as the ‘course textbook’ for the School of Data, and we need your help to make it as comprehensive and effective as possible! If you have experience with a particular tool, technique, process or pitfall, we’d love you to write a short chapter. The skeleton outline can be viewed online here – we will be fleshing out the details and adding content over the coming months. To offer feedback and to contribute, either (1) submit an issue to our tracker, (2) edit directly on Github, or (3) email schoolofdata [@] okfn.org with details of what you would like to add or change.
-
If you know of useful materials and resources, share them with us here. Datasets can be added directly to the School of Data group on the DataHub
-
If you would like to help edit, proof-read and test-run challenges and courses, sign up to the School of Data development mailing list, and introduce yourself. NB: there are two mailing lists! This one is higher traffic and interactive discussion is fully encouraged.
-
If you want to stay in touch with news about the School of Data, sign-up to the quieter announce list, or follow the School of Data on Twitter: @SchoolofData
Looking to the Future

Looking to the future, we hope that once the School of Data is established, volunteers and partner organisations may wish to:
- Act as mentors to help learners progress through School of Data courses
- Translate materials into more languages
- Support the School of Data in their local area – perhaps by running physical courses through local networks and organisations
- Volunteer to write specific courses
If you think you might be interested in getting involved in these or other ways, sign-up to the mailing list, and do drop an email to schoolofdata [@] okfn.org to introduce yourself.
[All images courtesy of Stefan Urabnek, @Stiivi]








The School has got off to a great start but, as recognised in the commentary about the skills map, won’t be able to address all of the skills in its first iteration. Obviously some priorities have to be decided.
As an enthusiastic layperson who’s read some of the draft handbook sections and attempted course 1 unsuccessfully, I see the need for some basic Excel/spread sheet training.
I read on the volunteers’ etherpad that Nick (Nvioli) is working on a course on data cleaning and basic spreadsheet skills.
Any idea when this may be ready and where it sits in the emerging SoD plan?
Thanks Gareth!
Nick’s draft course can be found here: https://p2pu.org/en/groups/data-cleaning-and-basic-spreadsheet-skills/. We’re really grateful to Nick for putting this together, and would love to hear your thoughts and feedback.
As the School of Data takes shape, we’ll be sure to include sufficient basic level courses to make sure that the needs of the ‘enthusiastic layman’ are fully catered for. This may well include more challenges to develop basic spreadsheet skills. Thanks for getting back to us about this!
Cheers,
Laura
Laura (and Nick) – thanks very much. I will start on the basic course today and let you know how I get on when there’s something to report back.
I may – or may not – be typical of interested citizens trying to do something with the public data now available, but I’m shocked by my own inability to get past the first hurdle. So I’m really hoping to gain some skills and insights from Nick’s course.
Keep up the great work
Gareth
Hey Gareth,
Thanks so much for your interest. I see you’ve gotten started; please let me know if you come across any questions or problems!
Best,
Nick