Recent years have seen a huge expansion in open data activity around the world. This is very welcome, but at the same time it is now increasingly difficult to assess if, and where, progress is being made.
To address this, we started the Open Data Census in order to track the state of open data globally. The results so far, covering more than 35 countries and 200 datasets, are now available online at http://census.okfn.org/. We’ll be building this up even more during Open Data Day this weekend.
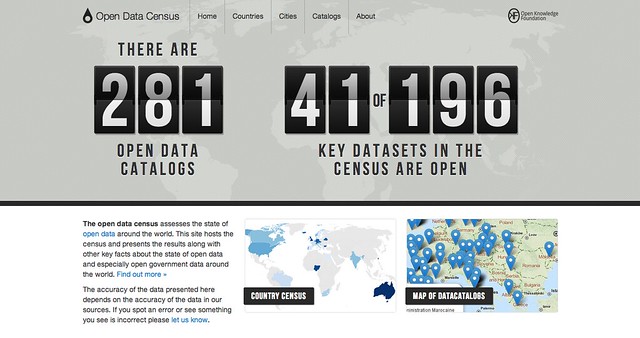
This post explains why we started the census and why this matters now. This includes the importance of quality (not just quantity) of data, the state of the census so far, and some immediate next steps – such as expanding the census to the city level and developing an “open data index” to give a single measure of open data progress.
Why the Census?
In the last few years there has been an explosion of activity around open data and especially open government data. Following initiatives like data.gov and data.gov.uk, numerous local, regional and national bodies have started open government data initiatives and created open data portals (from a handful 3 years ago there are now more than 250 open data catalogs worldwide).
But simply putting a few spreadsheets online under an open license is obviously not enough. Doing open government data well depends on releasing key datasets in the right way. Moreover, with the proliferation of sites it has become increasingly hard to track what is happening.
Which countries, or municipalities, are actually releasing open data and which aren’t?1 Which countries are making progress on releasing data on stuff that matters in the right way?
Quality not (just) Quantity
Progress in open government data is not (just) about the number of datasets being released. The quality of the datasets being released matters at least as much – and often more – than the quantity of these datasets.
We want to know whether governments around the world are releasing key datasets, for example critical information about public finances, locations and public transport rather than less critical information such as the location of park benches or the number of streetlights per capita.2
Similarly, is the data being released in a form that is comparable and interoperable or is it being release as randomly structured spreadsheets (or, worse, non-machine-readable PDFs)?
The essential point here is that it is about quality as much quantity. Datasets aren’t all the same, whether in size, importance or format.
Enter the Census
And so was born the Open Knowledge Foundation’s Open Data Census – a community-driven effort to map and evaluate the progress of open data and open data initiatives around the world.
We launched the first round of data collection last April at the meeting of the Open Government Partnership in Brazil. Since then members of the Open Knowledge Foundation’s Open Government Data Working Group have been continuing to collect the data and our Labs team have been developing a site to host the census and present its results.
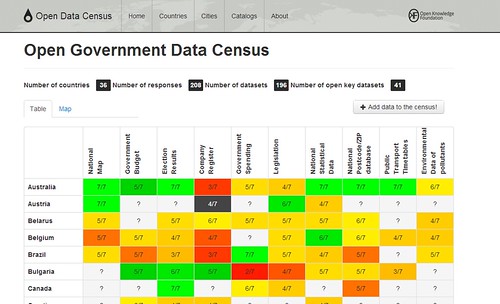
The central part of the census is an assessment based on 10 key datasets.
These were selected through a process of discussion and consultation with the Open Government Data Working Group and will likely be expanded in future (see some great suggestions from David Eaves last year). We’ll also be considering additional criteria: for example whether data is being released in a standard format that facilitates integration and reuse.
We focused on a specific list of core datasets (rather than e.g. counting numbers of open datasets) for a few important reasons:
- Comparability: by assessing against the same datasets we would be able to compare across countries
- Importance: Some datasets are more important than others and by specifically selecting a small set of key datasets we could make that explicit
- Ranking: we want, ultimately, to be able to rank countries in an “Open Data Index”. This is much easier if we have a good list of cross-country comparable data. 3
Today, thanks to submissions from more than thirty contributors the census includes information on more 190 datasets from more than 35 countries around the world and we hope to get close to full coverage for more than 50 countries in the next couple of months.
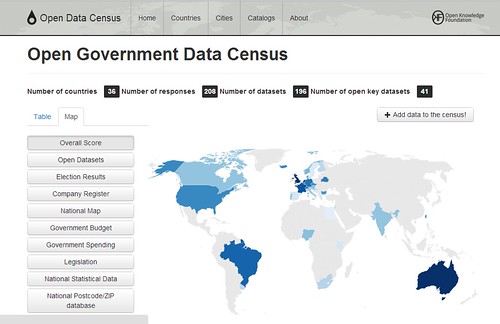
The Open Data Index: a Scoreboard for Open Government Data
Having the census allows us to evaluate general progress on open data. But having a lot of information alone is not enough. We need to ensure the information is presented in a simple and understandable way especially if we want it to help drive improvements in the state of open government data around the world.
Inspired by work such as Open Budget Index from the International Budget Partnership, the Aid Transparency Index from Publish What You Fund, the Corruption Perception Index from Transparency International and many more, we felt a key aspect is to distill the results into a single overall ranking and present this clearly. (We’ve also been talking here with the great folks at the Web Foundation, who are also thinking about an Open Data Index connected with their work on the Web Index).
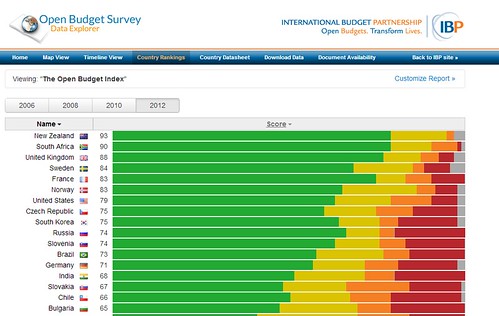
As part of our first work on the Census dashboard last September for OKFestival we did some work on an “open data index”, which provided an overall rankings for countries. However, during that work, it became clear that building a proper index requires some careful thought. In particular, we probably wanted to incorporate other factors than just the pure census results, for example:
- Some measure of the number of open datasets (appropriately calibrated!)
- Whether the country has an open government data initiative and open data portal
- Whether the country has joined the OGP
- Existence (and quality) of an FoI law
In addition, there is the challenging question of weightings – not only between these additional factors and census scores but also for scoring the census. Should, for example, Belarus be scoring 5 or 6 out of 7 on the census despite it not being clear whether any data is actually openly licensed? How should we weight total number of datasets against the census score?
Nevertheless, we’re continuing to work on putting together an “open data index” and we hope to have an “alpha” version ready for the open government data community to use and critique within the next few months. (If you’re interested in contributing check out the details at the end of this post).
The City Census
![]()
The first version of the census was country oriented. But much of the action around open data happens at the city and regional level, and information about the area around us tends to be the most meaningful and important.
We’re happy to say plans are afoot to make this happen!
Specifically, we’ll be kicking off the city census with an Open Data Census Challenge this Saturday as part of Open Data Day.
If the Open Data Census has caught your interest, you are invited to become an Open Data Detective for a day and help locate open (and closed) datasets in cities around the world. Find out more and sign up here: http://okfn.org/events/open-data-day-2013/census/
Get Involved
Interested in the Open Data Census? Want to contribute? There are a variety of ways:
- Contribute census results for a specific country
- Join the discussion on the Open Government Data working group mailing list
- Check the algorithms, fix a typo or help develop a new visualization on the Open Data Census site as a Github repo
- Use and explore the data
Notes
- For example, we’ve seen several open data initiatives releasing data under non-open licenses that restrict, for example, derivative works, redistribution or commercial use. ↩
- This isn’t to say that less critical information isn’t important – one of the key reasons for releasing material openly is that you never know who may derive benefit from it, and the “long tail of data” may yield plenty of unexpected riches. ↩
- Other metrics, such as numbers of datasets are very difficult to compare – what is a single dataset in one country can easily become a 100 or more in another country, for example unemployment could be in a single dataset or split into many datasets one for each month and region). ↩
Rufus Pollock is Founder and President of Open Knowledge.







