Tax justice advocates, global campaigners and open data specialists came together this week from across the world to work with Open Knowledge International on the first stages of creating a pilot country-by-country reporting database. Such a database may enable anyone to understand the activities of multinational corporations and uncover potential tax avoidance schemes.
This design sprint event was part of our Open Data for Tax Justice project to create a global network of people and organisations using open data to improve advocacy, journalism and public policy around tax justice in line with our mission to empower civil society organisations to use open data to improve people’s lives. In this post my colleague Serah Rono and I share our experiences and learnings from the sprint.
What is country-by-country reporting?

Country-by-country reporting (CBCR) is a transparency mechanism which requires multinational corporations to publish information about their economic activities in all of the countries where they operate. This includes information on the taxes they pay, the number of people they employ and the profits they report. Publishing this information can bring to light structures or techniques multinational corporations might be using to avoid paying tax in certain jurisdictions by shifting their profits or activities elsewhere.
In February 2017, Open Knowledge International published a white paper co-authored by Alex Cobham, Jonathan Gray and Richard Murphy which examined the prospects for creating a global public database on the tax contributions and economic activities of multinational companies as measured by CBCR.
The authors found that such a public database was possible and concluded that a pilot database could be created by bringing together the best existing source of public CBCR information – disclosures made by European Union banking institutions in line with the Capital Requirements Directive IV (CRD IV) passed in 2013. The aim of our design sprint was to take the first steps towards the creation of this pilot database.
What did we achieve?

A design sprint is intended to be a short and sharp process bringing together a multidisciplinary team in order to quickly prototype and iterate on a technical product.
On Monday 24th and Tuesday 25th July 2017, Open Knowledge International convened a team of tax justice, advocacy, research and open data experts at Friends House in London to work alongside developers and a developer advocate from our product team. This followed three days of pre-sprint planning and work on the part of our developers. All the outputs of this event are public on Google Drive, Github and hackmd.io.
To understand more from those who had knowledge of trying to find and understand CRD IV data, we heard expert presentations from George Turner of Tax Justice Network on the scale of international tax avoidance, Jason Braganza of Tax Justice Network – Africa and Financial Transparency Coalition on why developing countries need public CBCR (see report for more details) and Oliver Pearce of Oxfam Great Britain on the lessons learned from using CRD IV data for the Opening the vaults and Following the money reports. These were followed by a presentation from Adam Kariv and Vitor Baptista of Open Knowledge International on how they would be reusing open-source tech products developed for our Open Spending and OpenTrials projects to help with Open Data for Tax Justice.
Next we discussed the problems and challenges the attendees had experienced when trying to access or use public CBCR information before proposing solutions to these issues. This lead into a conversation about the precise questions and hypotheses which attendees would like to be able to answer using either CRD IV data or public CBCR data more generally.

As quickly as possible, the Open Knowledge International team wanted to give attendees the knowledge and tools they needed to be able to answer these questions. So our developers Georgiana Bere and Vitor Baptista demonstrated how anyone could take unstructured CRD IV information from tables published in the PDF version of banks’ annual reports and follow a process set out on the Github repo for the pilot database to contribute this data into a pipeline created by the Open Knowledge International team.
Datapackage-pipelines is a framework – developed as part of the Frictionless Data toolchain – for defining data processing steps to generate self-describing Data Packages. Once attendees had contributed data into the pipeline via Github issues, Vitor demonstrated how to write queries against this data using Redash in order to get answers to the questions they had posed earlier in the day.
Storytelling with CRD IV data
Evidence-based, data-driven storytelling is an increasingly important mechanism used to inform and empower audiences, and encourage them to take action and push for positive change in the communities they live in. So our sprint focus on day two shifted to researching and drafting thematic stories using this data.
Discussions around data quality are commonplace in working with open data. George Turner and Oliver Pearce noticed a recurring issue in the available data: the use of hyphens to denote both nil and unrecorded values. The two spent part of the day thinking about ways to highlight the issue and guidelines that can help overcome this challenge so as to avoid incorrect interpretations.
Open data from a single source often has gaps so combining it with data from additional sources often helps with verification and to build a stronger narrative around it. In light of this, Elena Gaita, Dorcas Mensa and Jason Braganza narrowed their focus to examine a single organisation to see whether or not this bank changed its policy towards using tax havens following a 2012 investigative exposé by a British newspaper. They achieved this by comparing data from the investigation with the bank’s 2014 CRD IV disclosures. In the coming days, they hope to publish a blogpost detailing their findings on the extent to which the new transparency requirements have changed the bank’s tax behaviour.
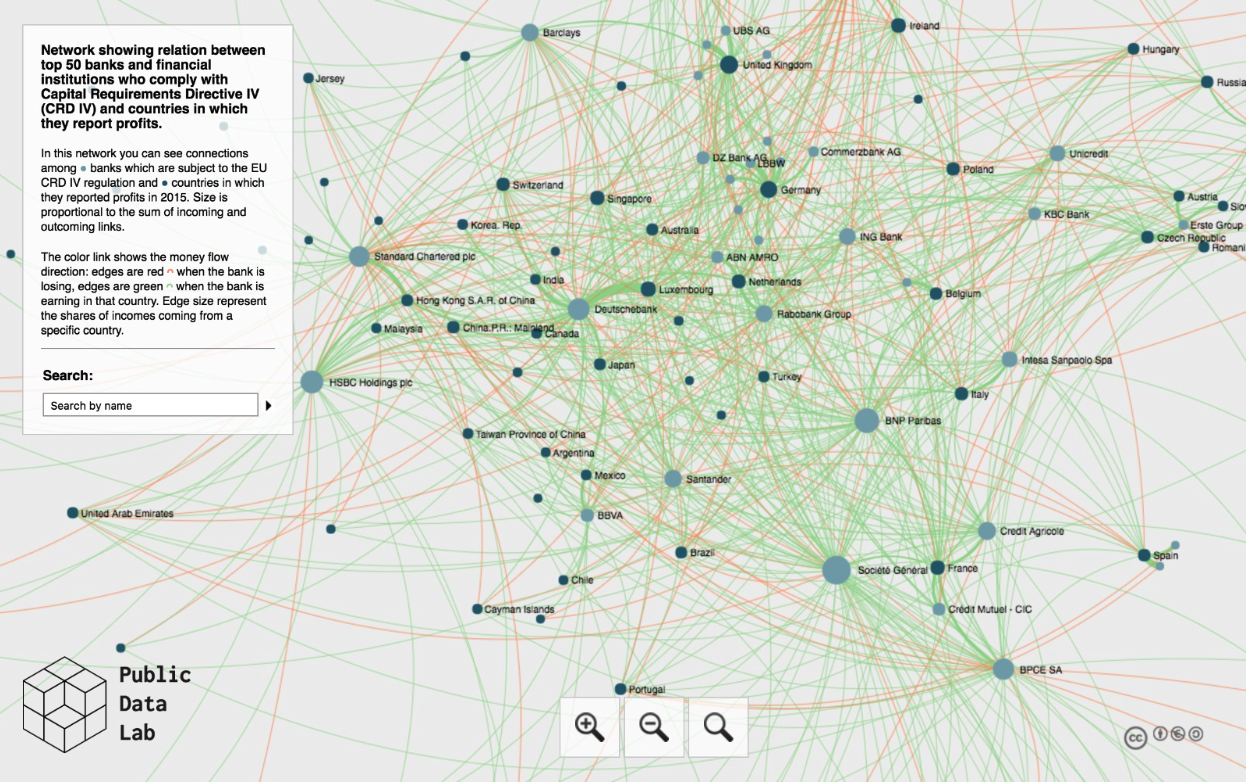
To complement these story ideas, we explored visualisation tools which could help draw insights and revelations from the assembled CRD IV data. Visualisations often help to draw attention to aspects of the data that would have otherwise gone unnoticed. Oliver Pearce and George Turner studied the exploratory visual network of CRD IV data for the EU’s top 50 banks created by our friends at Density Design and the Public Data Lab (see screengrab above) to learn where banks were recording most profits and losses. Pearce and Turner quickly realised that one bank in particular recorded losses in all but one of its jurisdictions. In just a few minutes, the finding from this visual network sparked their interest and encouraged them to ask more questions. Was the lone profit-recording jurisdiction a tax haven? How did other banks operating in the same jurisdiction fare on the profit/loss scale in the same period? We look forward to reading their findings as soon as they are published.
What happens next?
The Open Data for Tax Justice network team are now exploring opportunities for collaborations to collect and process all available CRD IV data via the pipeline and tools developed during our sprint. We are also examining options to resolve some of the data challenges experienced during the sprint like the perceived lack of an established codelist of tax jurisdictions and are searching for a standard exchange rate source which could be used across all recorded payments data.
In light of the European Union Parliament’s recent vote in favour of requiring all large multinational corporations to publish public CBCR information as open data, we will be working with advocacy partners to join the ongoing discussion about the “common template” and “open data format” for future public CBCR disclosures which will be mandated by the EU.
Having identified extractives industry data as another potential source of public CBCR to connect to our future database, we are also heartened to see the ongoing project between the Natural Resource Governance Institute and Publish What You Pay Canada so will liaise further with the team working on extracting data from these new disclosures.
Please email contact@datafortaxjustice.net if you’d like to be added to the project mailing list or want to join the Open Data for Tax Justice network. You can also follow the #OD4TJ hashtag on Twitter for updates.
Thanks to our partners at Open Data for Development, Tax Justice Network, Financial Transparency Coalition and Public Data Lab for the funding and support which made this design sprint possible.

![]()
![]()

Stephen Abbott Pugh was content development manager for the Open Knowledge Foundation.







