Frictionless Data is now in alpha at http://data.okfn.org/ – and we’d like you to get involved.
Our mission is to make it radically easier to make data used and useful – our immediate goal is make it as simple as possible to get the data you want into the tool of your choice.
This isn’t about building a big datastore or a data management system – it’s simply saving people from repeating all the same tasks of discovering a dataset, getting it into a format they can use, cleaning it up – all before they can do anything useful with it! If you’ve ever spent the first half of a hackday just tidying up tabular data and getting it ready to use, Frictionless Data is for you.
Our work is based on a few key principles:
- Narrow focus — improve one small part of the data chain, standards and tools are limited in scope and size
- Build for the web – use formats that are web “native” (JSON) and work naturally with HTTP (plain-text, CSV is streamable etc)
- Distributed not centralised — designed for a distributed ecosystem (no centralized, single point of failure or dependence)
- Work with existing tools — don’t expect people to come to you, make this work with their tools and their workflows (almost everyone in the world can open a CSV file, every language can handle CSV and JSON)
- Simplicity (but sufficiency) — use the simplest formats possible and do the minimum in terms of metadata but be sufficient in terms of schemas and structure for tools to be effective
We believe that making it easy to get and use data and especially open data is central to creating a more connected digital data ecosystem and accelerating the creation of social and commercial value. This project is about reducing friction in getting, using and connecting data, making it radically easier to get data you need into the tool of your choice. Frictionless Data distills much of our learning over the last 7 years into some specific standards and infrastructure.
What’s the Problem?
Today, when you decide to cook, the ingredients are readily available at local supermarkets or even already in your kitchen. You don’t need to travel to a farm, collect eggs, mill the corn, cure the bacon etc – as you once would have done! Instead, thanks to standard systems of measurement, packaging, shipping (e.g. containerization) and payment, ingredients can get from the farm direct to my local shop or even my door.
But with data we’re still largely stuck at this early stage: every time you want to do an analysis or build an app you have to set off around the internet to dig up data, extract it, clean it and prepare it before you can even get it into your tool and begin your work proper.
What do we need to do for the working with data to be like cooking today – where you get to spend your time making the cake (creating insights) not preparing and collecting the ingredients (digging up and cleaning data)?
The answer: radical improvements in the “logistics” of data associated with specialisation and standardisation. In analogy with food we need standard systems of “measurement”, packaging, and transport so that its easy to get data from its original source into the application where you can start working with it.
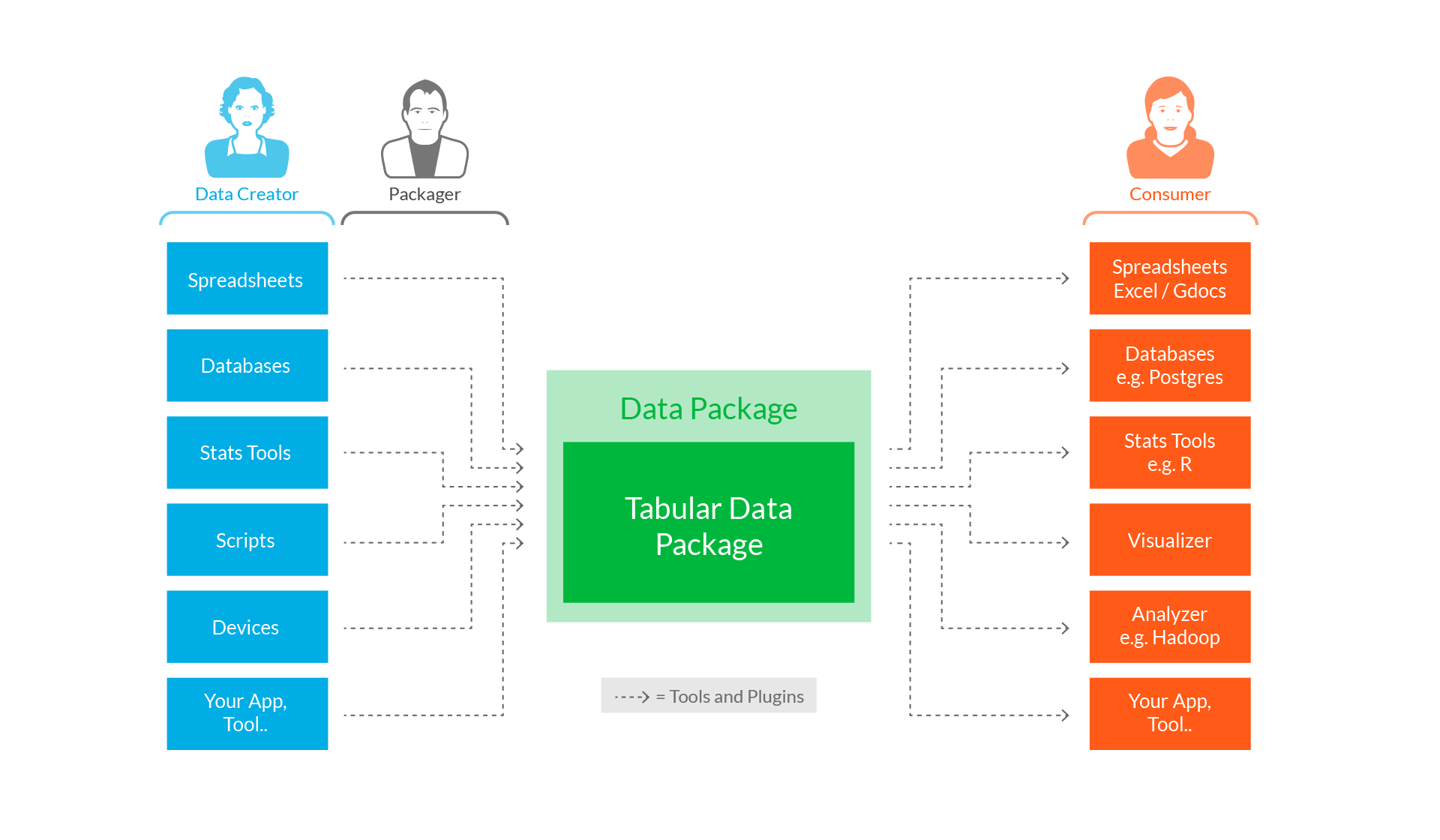
What’s Frictionless Data going to do?
We start with an advantage: unlike for physical goods transporting digital information from one computer to another is very cheap! This means the focus can be on standardizing and simplifying the process of getting data from one application to another (or one form to another). We propose work in 3 related areas:
- Key simple standards. For example, a standardized “packaging” of data that makes it easy to transport and use (think of the “containerization” revolution in shipping)
- Simple tooling and integration – you should be able to get data in these standard formats into or out of Excel, R, Hadoop or whatever tool you use
- Bootstrapping the system with essential data – we need to get the ball rolling
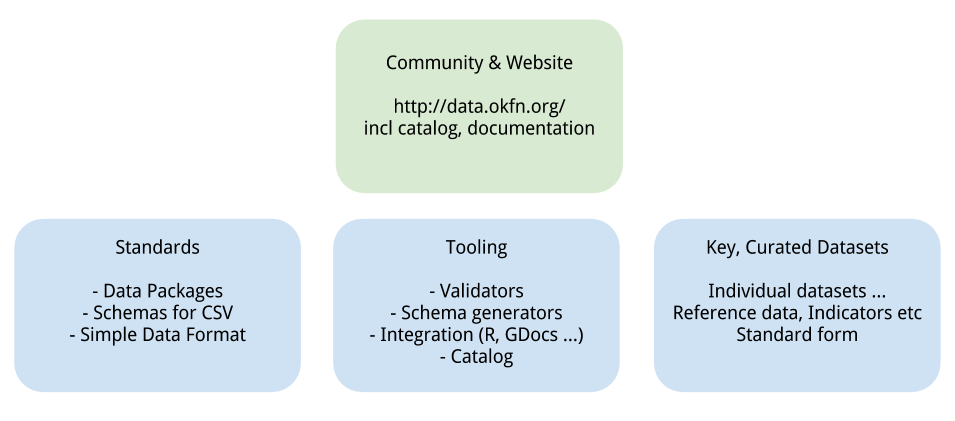
What’s Frictionless Data today?
1. Data
We have some exemplar datasets which are useful for a lot of people – these are:
- High Quality & Reliable
- We have sourced, normalized and quality checked a set of key reference datasets such as country codes, currencies, GDP and population.
- Standard Form & Bulk Access
- All the datasets are provided in a standardized form and can be accessed in bulk as CSV together with a simple JSON schema.
- Versioned & Packaged
- All data is in data packages and is versioned using git so all changes are visible and data can becollaboratively maintained.
2. Standards
We have two simple data package formats, described as ultra-lightweight, RFC-style specifications. They build heavily on prior work. Simplicity and practicality were guiding design criteria.
Data package: minimal wrapping, agnostic about the data its “packaging”, designed for extension. This flexibility is good as it can be used as a transport for pretty much any kind of data but it also limits integration and tooling. Read the full Data Package specification.
Simple data format (SDF): focuses on tabular data only and extends data package (data in simple data format is a data package) by requiring data to be “good” CSVs and the provision of a simple JSON-based schema to describe them (“JSON Table Schema”). Read the full Simple Data Format specification.
3. Tools
It’s early days for Frictionless Data, so we’re still working on this bit! But there’s a need for validators, schema generators, and all kinds of integration. You can help out – see below for details or check out the issues on github.
Doesn’t this already exist?
People have been working on data for a while – doesn’t something like this already exist? The crude answer is yes and no. People, including folks here at the Open Knowledge Foundation, have been working on this for quite some time, and there are already some parts of the solution out there. Furthermore, much of these ideas are directly borrowed from similar work in software. For example, the Data Packages spec (first version in 2007!) builds heavily on packaging projects and specifications like Debian and CommonJS.
Key distinguishing features of Frictionless Data:
- Ultra-simplicity – we want to keep things as simple as they possibly can be. This includes formats (JSON and CSV) and a focus on end-user tool integration, so people can just get the data they want into the tool they want and move on to the real task
- Web orientation – we want an approach that fits naturally with the web
- Focus on integration with existing tools
- Distributed and not tied to a given tool or project – this is not about creating a central data marketplace or similar setup. It’s about creating a basic framework that would enable anyone to publish and use datasets more easily and without going through a central broker.
Many of these are shared with (and derive from) other approaches but as a whole we believe this provides an especially powerful setup.
Get Involved
This is a community-run project coordinated by the Open Knowledge Foundation as part of Open Knowledge Foundation Labs. Please get involved:
- Start using the standards, data and tools
- Contribute data: instructions here
- Test and develop tooling and integration
- Get involved in the discussion and community at Open Knowledge Labs:
- Spread the word! Frictionless Data is a key part of the real data revolution – follow the debate on #SmallData and share our posts so more people can get involved
Rufus Pollock is Founder and President of Open Knowledge.








Good work! I tried implementing the standard, but got confused soon:
http://data.kartverket.no/stedsnavn/GeoJSON/datapackage.json
What is the suggested format of the “hash” field?
Now in the assesment criteria you suddenly say that data should be CSV only. The datapackage standard talks about the simple table schema for JSON. How about GeoJSON properties?
I submitted a few issues in the tracker. Looking forward to work on this.
Great points and I’ve already replied to some of them in the tracker. I note that Data Packages can transport any kind of data (including geojson) but for Simple Data Format it must be CSV.
Could you elaborate how this differs from OASIS OData work?
Crudely the differences are:
a) OData is oriented to API support whilst the formats mentioned here say nothing about API structure but are focused on (bulk) “transport”.
b) OData is Atom + JSON based whilst Data Package says nothing about the data structure and Simple Data Format requires CSV as the Data Structure.
c) OData is much more detailed regarding schemas – Simple Data Format is (intentionally) very simple.
d) OData does require a specialist library or tool to handle whilst Data Package and Simple Data Format attempt to largely build on format that are already easily processable (or degrade to such formats)
Wouldn’t it be more frictionless if you seperate classification from item? E.g. providing a list of countries and their data, not a dataset containing both country and region. Or if you need to do so, at least add a variable indicating wether the data are for regions or countries. Also, in ten datasets, you use two different codes for countries. We need common standards for one concept, right? Or at least translation tables between codings.
@twitter-356089631:disqus good comments. Could you point out the datasets you mean (and, even better, raise issues on them – see the “report issue” on each dataset page).
Re the country codes: would love to fix this – again please just raise an issue on the relevant dataset!