










































Don't miss a thing! Stay on top of what's happening in the #OpenMovement around the world.
European Commission VP’s roundtable: influencers in the fight against misinformation
An account of Věra Jourová’s official visit to Greece and the need for open data to combat disinformation.
Read moreOpen Data Editor: 5 tips for building data products that work for people
As announced in January, this year the Open Knowledge Foundation (OKFN) team is working to develop a stable version of the Open Data Editor (ODE) application. Thanks to financial support from the Patrick J. McGovern Foundation, we will be able to create a no-code tool for data manipulation and publishing that is accessible to everyone, […]
Read more#ODDStories 2024 @ Kathmandu, Nepal 🇳🇵
Check Open Tech Community Nepal’s report on their event held with the help of an Open Data Day mini-grant.
Read moreOpen Knowledge Network: Introducing the Regional Hubs Prototype Programme
We’re thrilled to unveil today the latest addition to our Network, a programme to foster collaboration and expand our reach and impact across the globe.
Read more#ODDStories 2024 @ Kigali City, Rwanda 🇷🇼
Check out EcoMappers’ report on their event held with the help of an Open Data Day mini-grant.
Read moreEmpowering Communities: Open Knowledge Somalia’s Open Street Mapping Workshop
The workshop aimed to enlighten attendees on the fundamentals and applications of open street mapping, a collective method for creating and refining maps with freely accessible geographic data.
Read more#ODDStories 2024 @ Guatemala City 🇬🇹
Check out Diálogos’ report on their event held with the help of an Open Data Day mini-grant.
Read moreOpen Data Editor: meet the team behind the app
Join us on this learning journey and follow the details of the app’s development in this series of blogs.
Read moreThe Republic of the Congo opts for the use of biometrics in multi-party elections
The political will to use biometrics as a means of peacefully resolving political disputes and strengthening the credibility of multi-party elections should be seized as an opportunity for the international community.
Read more#ODDStories 2024 @ Kibaale, Uganda 🇺🇬
Check out Rural Aid Foundation’s report on their event held with the help of an Open Data Day mini-grant.
Read moreOpen Data Editor: what we learned from user research
Join us on this learning journey and follow the details of the app’s development in this series of blogs.
Read more#ODDStories 2024 @ Detroit, USA 🇺🇸
Check out DETROITography’s report on their event held with the help of an Open Data Day mini-grant.
Read more#ODDStories 2024 @ Bandung, Indonesia 🇮🇩
Check out the UPI Youthmappers’ report on their event held with the help of an Open Data Day mini-grant.
Read more#ODDStories 2024 @ Caracas, Venezuela 🇻🇪
Check out Utopix’s report on their event held with the help of an Open Data Day mini-grant.
Read more#ODDStories 2024 @ Marsabit, Kenya 🇰🇪
Check out the Pastoralist Peoples’ Initiative’s report on their event held with the help of an Open Data Day mini-grant.
Read more#ODDStories 2024 @ Milan, Italy 🇮🇹
Check out the Geodetic and Photogrammetric Laboratory’s report on their event held with the help of an Open Data Day mini-grant.
Read more#ODDStories 2024 @ Quezon City, Philippines 🇵🇭
Check out the UP Resilience Institute YouthMappers’s report on their event held with the help of an Open Data Day mini-grant.
Read moreAngela Oduor Lungati: ‘When embracing open source, one must be intentional about being inclusive’
The Executive Director of Ushahidi joins us for the ninth #OKFN100, a series of conversations about the challenges and opportunities facing the open movement.
Read more#ODDStories 2024 @ Belém, Brazil 🇧🇷
Check out the Meninas da Geo’s report on their event held with the help of an Open Data Day mini-grant.
Read more#ODDStories 2024 @ Kwara, Nigeria 🇳🇬
Check out the Learnovation Foundation Network’s report on their event held with the help of an Open Data Day mini-grant.
Read moreOpen Data Day 2024 – Global Statistics & Activity Report
This year’s Open Data Day (ODD) was a huge success. Almost 300 events registered worldwide, with 60 countries participating in 15+ different languages. Check out the report.
Read moreRebecca Firth: ‘A panacea of open data is needed to tackle climate-related disasters’
The Executive Director of Humanitarian OpenStreetMap Team joins us for the eighth #OKFN100, a series of conversations about the challenges and opportunities facing the open movement.
Read moreAnd the winners of the Open Data Day 2024 Mini-Grants are. . .
We at the Open Knowledge Foundation (OKFN) are excited to announce the list of organisations that have been awarded mini-grants to help them host Open Data Day (ODD) events and activities across the world.
Read moreOpen Data Day 2024 – Mini-Grants Open Call
We are excited to announce the launch of the Open Data Day 2024 Mini-Grants Application to support organisations hosting open data events and activities across the world.
Read moreOpen Knowledge Network Regional Hubs Coordinators – Call for Applications
Are you a community practitioner or a researcher interested in international networks and the digital commons? This could be an interesting opportunity for you.
Read moreAnnouncement of strategic funding for the Open Data Editor
We are pleased to announce that the Open Knowledge Foundation has been selected as a grantee of the Patrick J. McGovern Foundation, marking a significant milestone for the development of the Open Data Editor (ODE) application, a tool that will unlock the power of data for key groups, including scientists, journalists and data activists.
Read moreEnd of the year with the Open Knowledge Network
Before we get to 2024, check out the heart-warming updates from around the world by the members of the Open Knowledge Network.
Read moreThe South at the world’s centre: OKFN dive into Uruguay’s data marathon
At the beginning of November, I visited Uruguay in the capacity of Open Knowledge Foundation’s Partnerships Lead to take part in #MaratónDeDatos, a pool of various events focused on the work with data, open data and open knowledge, and a meeting point for the global community engaged with the topic. I first arrived in Montevideo […]
Read moreHow DPI can help fight Information Pollution during elections
Our workshop in Ethiopia with DPGA members detected misinformation in three stages of the electoral process: voters’ registration, campaigns, and election day. Check out the results.
Read moreDebriefing the 4th round table for a Digital Public Infrastructure for Electoral Processes [Francophone Africa]
Last Wednesday, 22 November, Open Knowledge Foundation and AfroLeadership organised a round table on Digital Public Infrastructure (DPI) for Electoral Processes, focusing on initiatives developed in Francophone Africa. This was the fourth round table in the framework of this initiative, with which we are trying to map the initiatives and projects already active in the […]
Read moreCsv,conf is going to Mexico!
The most beloved community conference for datamakers from all around the world is back in May 2024! After a very successful seventh edition in Buenos Aires in April 2023, we have decided to linger a little longer in Latin America. We are very excited to announce that csv,conf,v8 will take place in Mexico! The commallama […]
Read moreDebriefing the 3rd round table for a Digital Public Infrastructure for Electoral Processes [Anglophone Africa]
Last Wednesday, November 15th, we had the pleasure of organising the third round table to share experiences related to the development of open digital technologies and data standards in electoral processes, with a focus on initiatives from Anglophone Africa. Beyond presenting our new initiative, the main objective of the event was to listen to and […]
Read moreFrictionless specs update
Originally published on: https://frictionlessdata.io/blog/2023/11/15/frictionless-specs-update/ We are very pleased to announce that thanks to the generous support of NLnet we have kickstarted the Frictionless specifications update. After a first discussion with the community in the last call, we are setting up a working group to help us with the v2 release. Taking into account the group’s concerns about the […]
Read moreDebriefing the 2nd round table for a Digital Public Infrastructure for Electoral Processes [North America, Europe, Bangladesh]
The main objective of the panel was to listen to and learn about the local perspectives of each participant, in hopes of identifying common ground and possibilities for collaboration. Access the video and summary.
Read moreNew Release: Problematising Strategic Tension Lines in the Digital Commons
As a part of our exploration of the open movement, last May, we hosted a workshop with a small group of the movement’s leaders. It was co-organised by our partners at Open Future and Wikimedia Europe. The convening built up on what was found out in Shifting Tides – quality research about the state of the movement conducted […]
Read moreHow a Public Digital Infrastructure for Electoral Processes is Helping Argentina Combat Disinformation
The National Electoral Directorate of Argentina has taken a significant step, and we are pleased to see, once again, how access to open knowledge helps different governments strengthen their democratic processes.
Read moreDebriefing the 1st round table for a Digital Public Infrastructure for Electoral Processes [Latin America]
The main objective of the panel was to listen to and learn about the local perspectives of each participant, in hopes of identifying common ground and possibilities for collaboration. Access the video and summary.
Read moreUrgent Call for Tech Companies to Respect Palestinian Digital Rights in Times of Crisis
We, a collective of human rights and civil society organizations, urge tech companies to immediately take strict measures to protect their users from harm in light of the escalating events in the region. These events have inevitably led to increased discrimination against Palestinian content and a rise in anti-Palestinian racism across various online platforms, and […]
Read moreOpen Knowledge Foundation joins the Digital Public Goods Alliance
By uniting resources and expertise, OKFN and DPGA aim to harness the power of digital commons to advance the Sustainable Development Goals (SDGs).
Read moreIntroducing Open Data Editor (beta): Towards a No-Code Data App for Everyone
OKFN is thrilled to introduce the initial version of the Open Data Editor (beta) today. We hope it will become in the future a no-code, easy-to-use application to explore and publish all kinds of data.
Read moreThe Tech We Want to Open Governments
On September 4th, Open Knowledge Foundation, together with Open Knowledge Estonia and Open Knowledge Finland, held a parallel event to the Global Open Government Partnership Summit in Tallinn to talk about the tech we want (and need) to open governments.
Read moreOGP remarks: lots of open government, not so much FOIA, congruency missing
Check out the observations of our developer and long-life open activist Patricio Del Boca after attending the OGP for the first time: “We should start practicing what we preach”
Read moreStefania Maurizi: ‘Secrets are the currency of power’
One of the most important investigative journalists working as a media partner of WikiLeaks joined us for the seventh #OKFN100, a series of conversations about the current challenges and the paths of action of the open movement
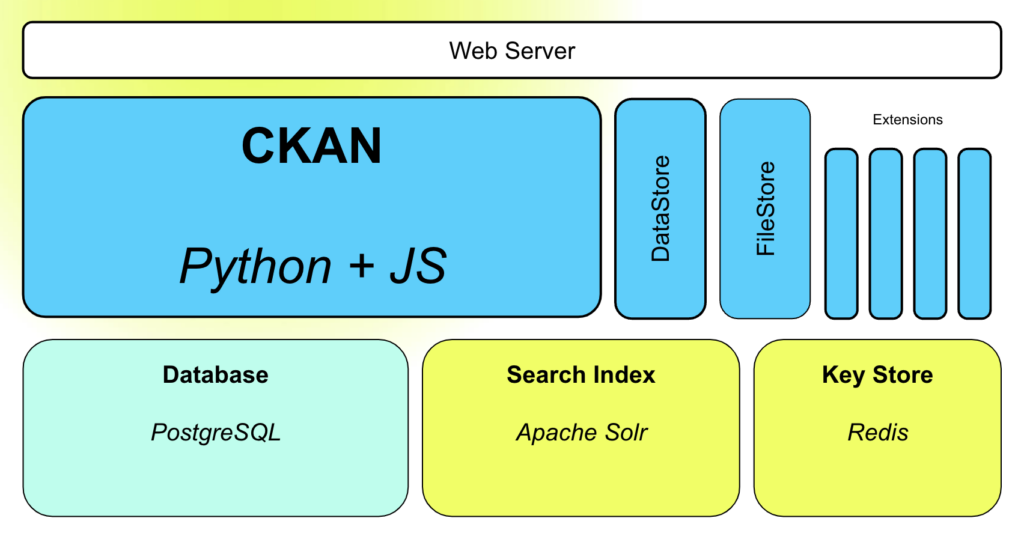
Read moreData-driven Development in Latin America and the Caribbean: A Recap of the CKAN Workshop at Code4Dev
Watch the workshop recording and learn the basics about an open data portal implementation using CKAN. This training was offered by Open Knowledge in partnership with the Inter-American Development Bank.
Read moreCalling South Asian communities involved with open knowledge
We at OKFN are preparing another round of consultations on updating the “Open Definition”, now at Wikimania Singapore.
Read more#OpenGovRetrospective – Get inspired by projects from our global Network
Latest update: August 21, 2023 The Open Government Partnership (OGP) Global Summit 2023 is fast approaching. As we prepare to run an official side event, Open Knowledge Foundation has been reviewing all the open government projects we’ve launched or been involved with in recent years. As the projects list keeps growing, we decided to take […]
Read moreBetter together: debriefing the Open Knowledge Network annual meeting in Zurich
At the annual meeting, our Network deepened connections, identified key areas to work together and jointly developed a vision for the future of the movement.
Read more#OpenGovRetrospective – What we’ve done inspires what comes next
Join us in looking back on open government past projects and in re-igniting the conversations in such a challenging time for democracies.
Read moreSwitzerland becomes the epicenter of open knowledge for a few days
Members of the Open Knowledge Network met in Zürich last week at Opendata.ch annual forum.
Read moreDebriefing the Open Definition workshop at RightsCon
Three weeks ago at RightsCon Costa Rica, we continued the process of rethinking and updating the Open Definition for today’s challenges and contexts. Here are the main takeaways.
Read more-

-

-

-

-

-

-

-
-

This work is licensed under a Creative Commons Attribution 4.0 International License.